2024. 12. 12. 02:05ㆍCS/DB
1. 디스크(Disk)
- 디스크는 순차 접근(sequential access)가 아닌 직접 접근(direct access)를 지원한다.
- 디스크는 데이터를 블록(block) 단위로 저장하며, 디스크와 메모리 간 데이터 전송도 블록 단위로 이루어진다.
접근 시간(I/O 비용) = 탐색 시간(Seek Time) + 회전 지연(Rotational Delay) + 전송 시간(Transfer Time)
- 탐색 시간(Seek Time): 디스크 헤드가 원하는 블록의 트랙으로 이동하는 시간 (일반적으로 플래터의 지름에 비례)
- 회전 지연(Rotational Delay): 원하는 블록이 디스크 헤드 아래로 올 때까지 플래터가 회전하는 시간
- 전송 시간(Transfer Time): 블록의 데이터를 읽거나 쓰는 시간
위 수식에서 알 수 있듯이, 접근 시간은 디스크에 데이터를 저장하는 방식에 큰 영향을 받으므로, 데이터를 전략적으로 배치해야 한다.
예를 들어, 임의의 두 데이터가 자주 함께 사용된다면, 다음과 같은 순서로 배치하는 것이 효율적이다: 같은 블록 > 같은 트랙 > 같은 실린더 > 인접한 실린더

2. 디스크 공간 관리자(Disk Space Manager)
- 디스크 공간 관리자는 디스크 공간을 페이지 단위로 할당 및 해제하고, 블록에 읽기 및 쓰기 작업을 수행하며 디스크 공간을 관리한다. 예를 들어, 자주 함께 사용되는 페이지들은 연속된 블록에 배치하여 디스크 공간을 효율적으로 관리한다.
디스크 공간 관리자가 빈 블록(Free Block)을 관리하는 방법
1. 연결 리스트(Linked List): 빈 블록을 모아두는 빈 블록 리스트를 사용한다.
2. 비트맵(Bitmap): 블록의 사용 여부를 나타내는 1비트 크기의 비트맵을 사용한다. (1 = 사용 중, 0 = 비여 있음)
3. 버퍼 관리자(Buffer Manager)
- 버퍼 관리자는 디스크에서 메모리로 페이지를 읽어오는 혹은 디스크에 페이지를 기록(저장)하는 역할을 수행한다.
- 버퍼 풀(Buffer Pool)은 버퍼 관리자가 메모리 내에서 사용 가능한 공간으로 프레임(frame) 단위를 사용한다. 프레임은 페이지를 적재할 수 있는 슬롯으로 이해하면 좋다.
- 버퍼 풀 크기는 제한적이기 때문에 필요한 모든 페이지를 버퍼 풀에 불러오지 못할 수 있다. 이 경우, 교체 정책(Replacement Policy)으로 교체할 페이지(=버퍼 풀에서 나갈 페이지)를 결정해야 한다.
- 버퍼 관리자는 각 프레임에 대해 두 가지 상태 변수를 관리한다: pin_count: 현재 사용 중인 횟수, 터디(dirty) 비트: 페이지 수정 여부
pin_count가 0이 되지 않으면 해당 페이지는 교체 후보에서 제외된다. 페이지가 수정되면 해당 프레임을 un-pin할 때 페이지 수정 사실을 알려 터디 비트를 활성화해야 한다. 교체할 프레임에 터디 비트가 활성화되어 있는 경우에는 수정사항을 디스크에 반영해야 한다.
- 잠금 프로토콜(Locked Protocal)을 사용해 특정 페이지가 동시에 수정하는 것을 막는다. 페이지를 읽거나 쓰기 위해서는 공용 잠금(Shared Lock) 또는 전용 잠금(Exclusive Lock) 권한을 가져와야 하기 때문에, 동시 수정 문제가 방지할 수 있다. (해당 내용은 5. 트랜잭션 글에서 자세히 다룰 것이다.)
교체 정책
1. LRU(Least Recently Used): pin_count가 0인 프레임 중 가장 오랫동안 사용되지 않은 프레임을 교체한다. (큐로 구현 가능)
2. MRU(Most Recently Used): pin_count가 0인 프레임 중 가장 최근에 사용된 프레임을 교체한다. (스택으로 구현 가능)
3. Clock: current 변수를 사용해 버퍼 풀 프레임을 순환하며 교체 조건을 충족하는 프레임을 찾는다.
각 프레임은 referenced 비트를 가지며 pin_count가 0이 될 때 활성화된다. pin_count가 0이고, referenced 비트가 비활성화되어 있으면 조건을 충족해 교체 프레임으로 선정된다. 만약 pin_count가 0인데 referenced가 활성화되어 있으면 비활성화시킨 후 다음 프레임으로 이동한다.
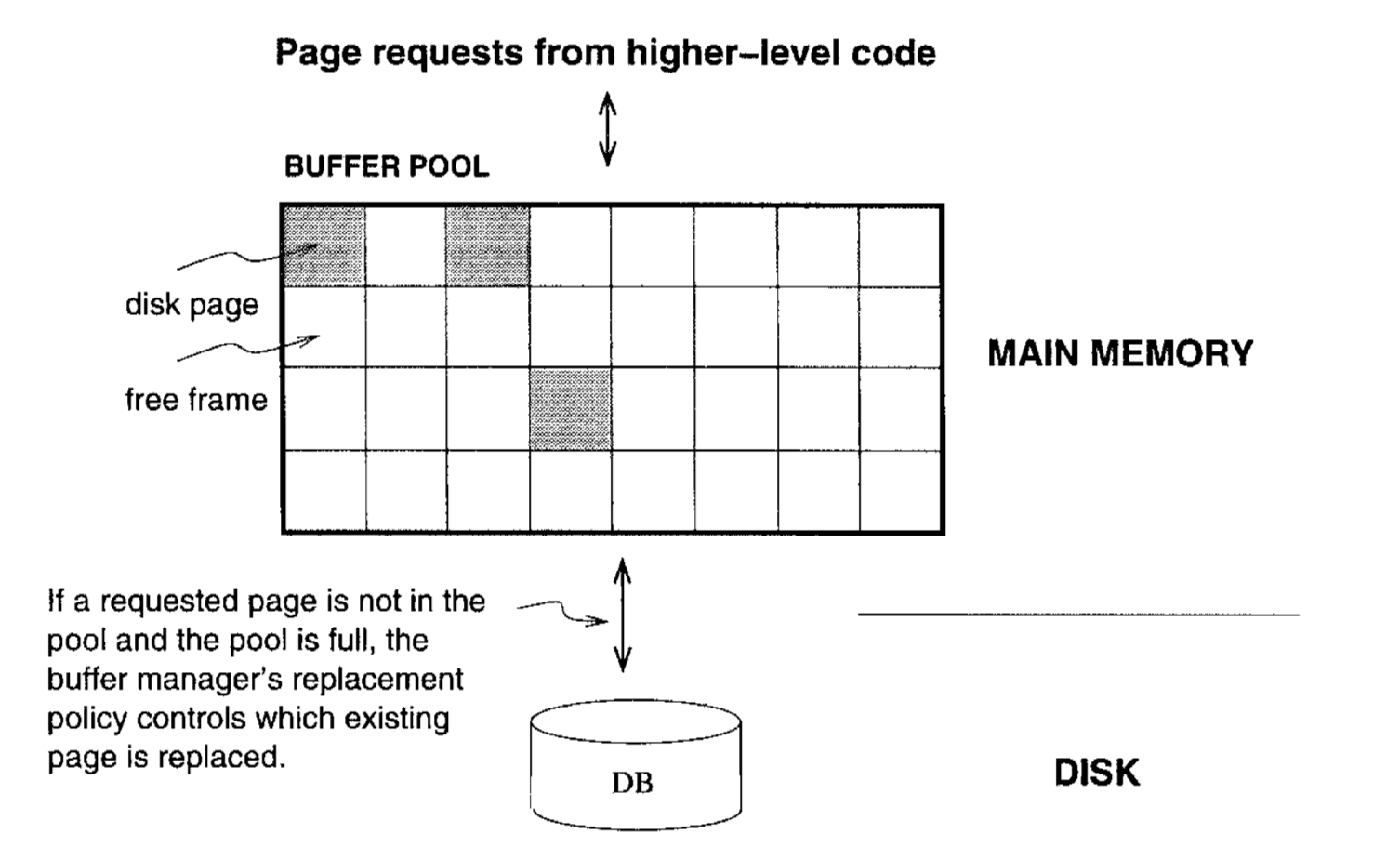
DBMS vs OS
DBMS가 OS의 버퍼 관리자를 사용하지 않는 이유는, 페이지 접근 순서(Page Reference Pattern)를 더 정확히 예측할 수 있는 DBMS 특성을 활용하기 위해서다.
대표적으로, 참조 패턴을 예측하여 필요한 페이지를 미리 가져올(pre-fetching) 수 있고, 이는 CPU 연산과 병렬로 수행할 수 있게 해줘 작업 시간을 단축시켜준다.
4. 레코드 파일(Record File)
파일, 페이지, 레코드 저장 방법에 대해 살펴볼 것이다.
4.1. 파일(File)
파일은 자신에게 할당된 페이지를 뿐만 아니라, 그 중 빈 공간이 있는 페이지도 파악해야 한다.
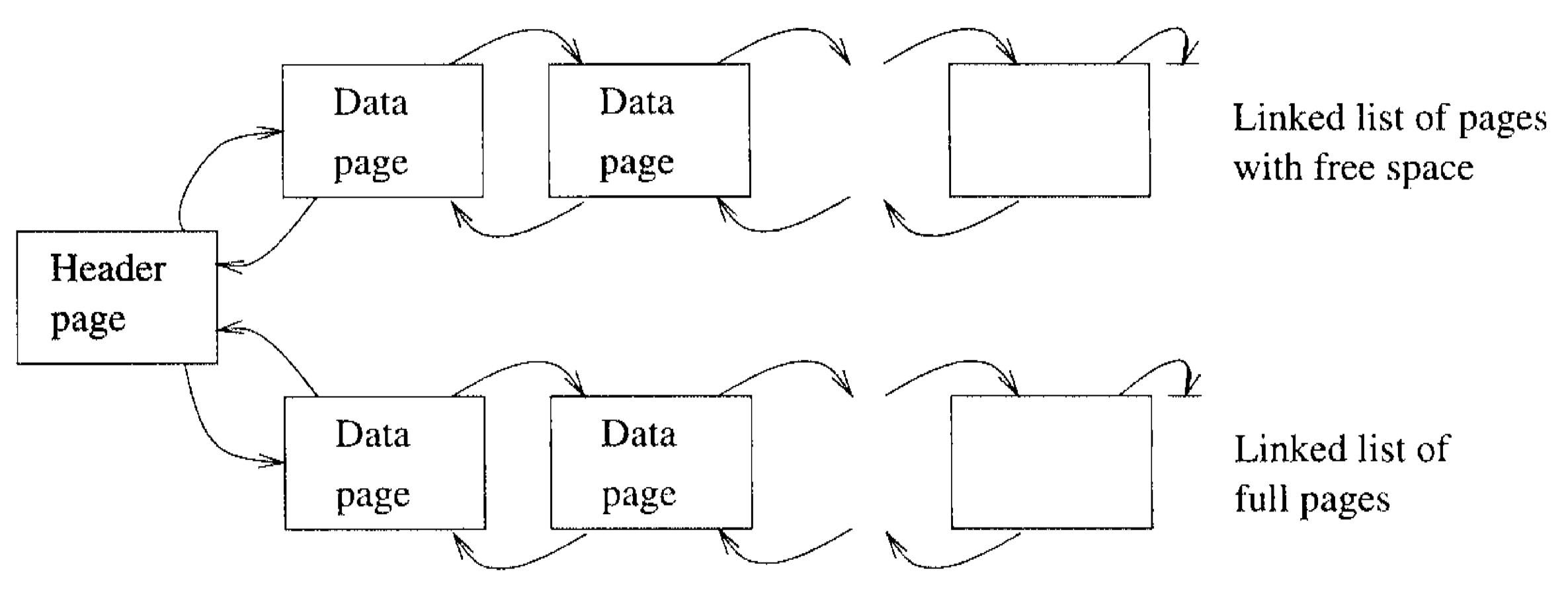
4.1.1. 연결 리스트 기반 페이지(Linked List of Pages)
빈 공간이 있는 페이지와 가득 찬 페이지에 대한 각각의 이중 연결 리스트를 사용하는 방식이다. 이때, DBMS는 <파일 이름, 첫 페이지 주소>으로 구성된 테이블을 유지하며 파일 위치를 파악한다.
단점: 레코드가 가변 길이인 경우, 대부분의 페이지에 약간의 빈 공간이 남는다. 따라서, 레코드를 삽입하려면 빈 공간이 충분한 있는 페이지를 찾기 위해 여러 페이지를 확인해야 한다.
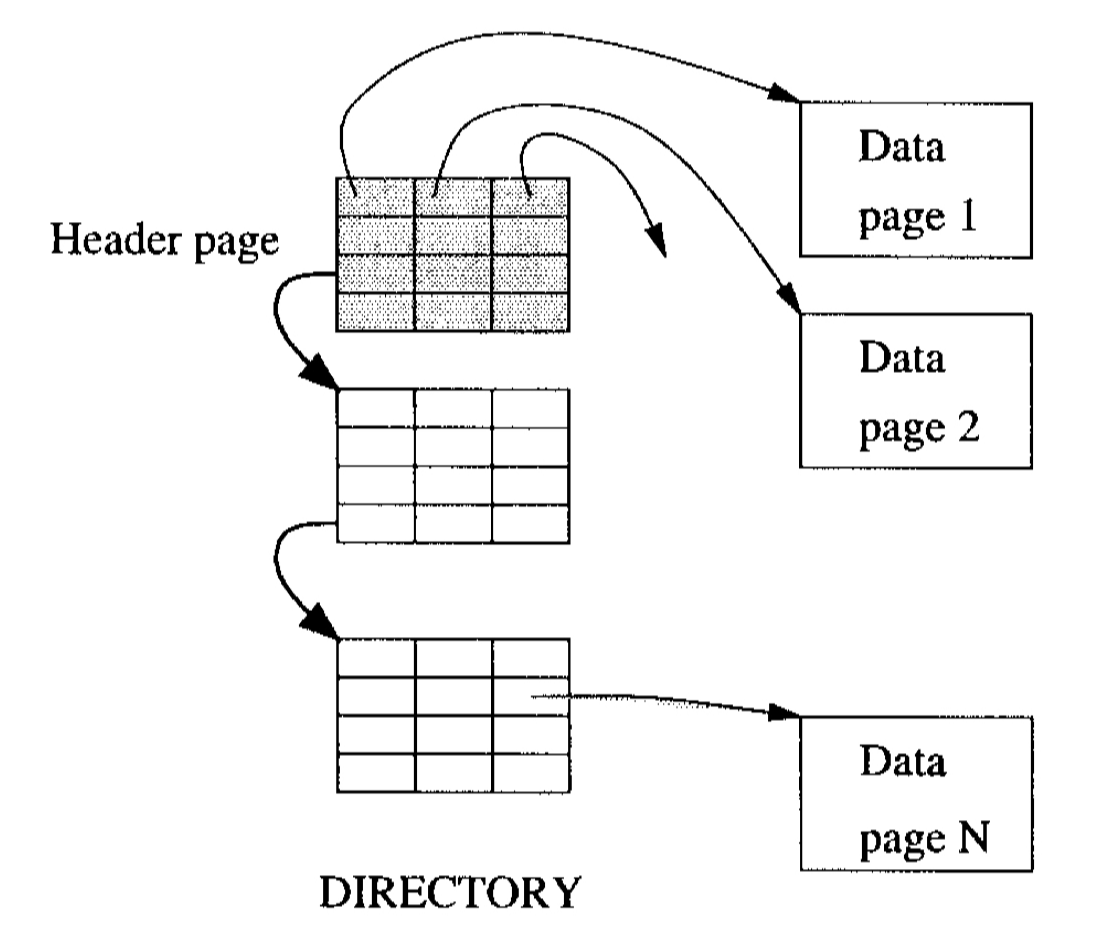
4.1.2. 디렉토리 기반 페이지(Directory of Pages)
페이지의 디렉토리(directory of pages)를 사용하는 방식이다. 이때, DBMS는 <파일 이름, 첫 디렉토리 페이지 주소>으로 구성된 테이블을 유지하며 파일 위치를 파악한다.
각 디렉토리 항목이 하나의 페이지를 식별 및 참조하는 역할을 한다.
빈 공간 여부는 각 항목에 유무를 확인할 수 있는 비트 혹은 빈 공간의 양을 나타내는 free space count로 관리할 수 있다.
이 방식은 각 항목의 free space count를 확인하여 삽입 가능 여부를 판단할 수 있으므로 효율적이다.
4.2. 페이지(Page)
레코드 집합이 페이지 상에 어떻게 배열될 수 있는지 알아봅시다.
- 페이지는 슬롯의 집합으로 볼 수 있는데, 각 슬롯은 하나의 레코드를 가지고 있다.
- 레코드는 <페이지 id, 슬롯번호>를 사용해 식별되는데 이를 record-id(rid)라고 한다.
4.2.1. 고정 길이 레코드(fixed-length records)
모든 레코드가 동일한 길이를 가지고 있다면, 균등한 레코드 슬롯을 사용해 페이지 내에 연속적으로 배열하는 방식을 주로 사용한다.
이때, 페이지 상에 있는 빈 슬롯과 모든 레코드들의 위치를 파악(관리)해야 하며, 관리 방법에 따라 삭제 연산 방식에 차이가 발생한다.
삭제 연산 방식:
1. 페이지 내의 마지막 레코드를 삭제된 레코드 슬롯으로 이동시킨다.
단점: 이동하는 레코드에 대한 외부의 참조가 존재하는 경우 쓸 수 없다.
2. 빈 슬롯을 파악하기 위해 슬롯 당 한 비트씩 할당된 배열을 사용해 삭제 연산을 수행한다.
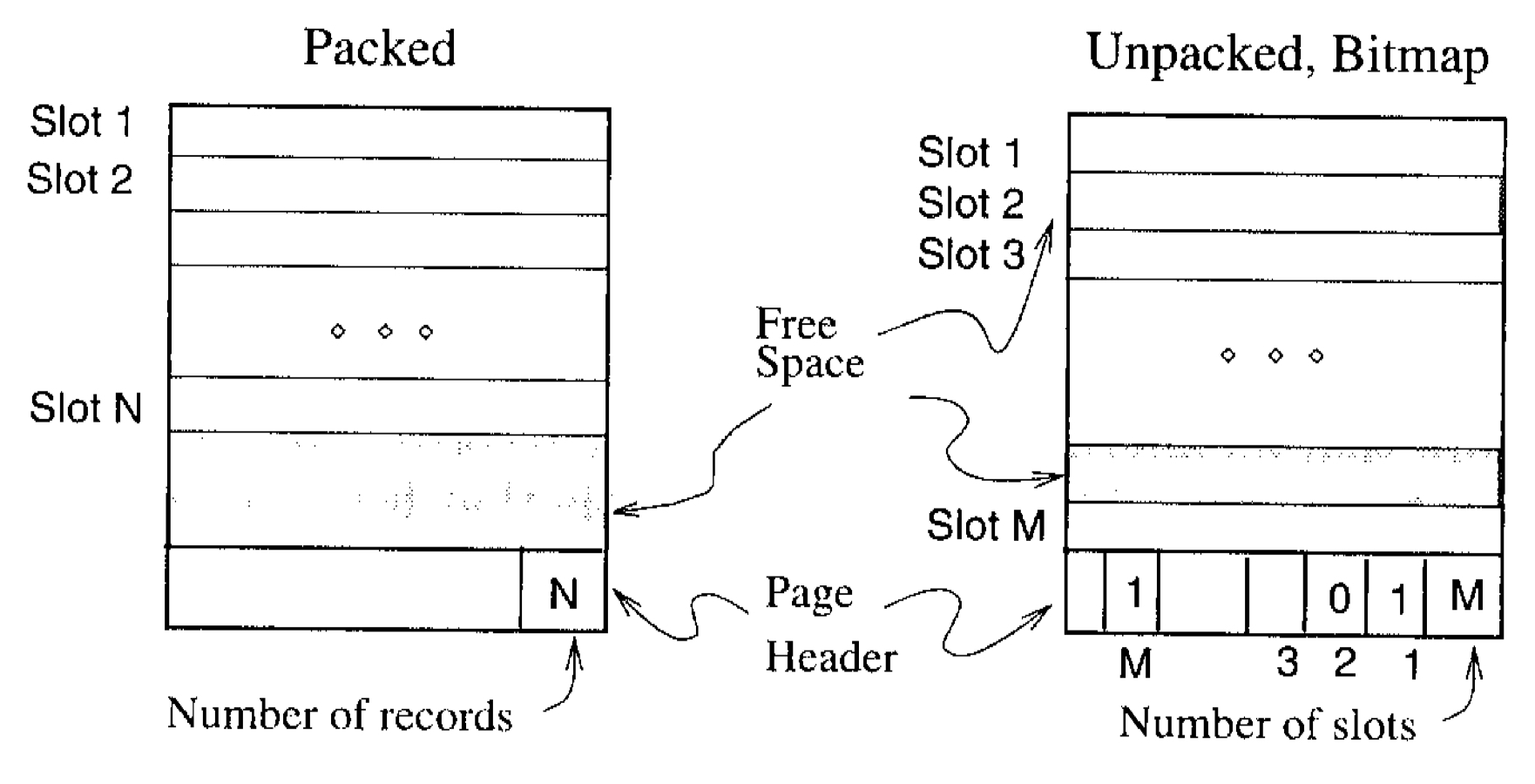
해당 그림과는 다르게, 각 페이지에는 레코드 자체에 관한 정보 뿐만 아니라 파일 레벨의 정보까지 포함되어 있다.
4.2.2. 가변 길이 레코드(variable-length records)
슬롯 당 <레코드 포인터, 레코드 길이> 쌍을 포함하는 슬롯 디렉토리(slot directory)를 사용해 가변 길이 레코드를 저장하는데 사용한다.
삭제 연산은 레코드 포인터를 -1로 설정하는 방식으로 처리한다. rid는 페이지 번호와 슬롯 번호로 구성되므로, 페이지 내에서 레코드를 이동시켜도 rid가 변하지 않는다. 즉, 자유롭게 이동 가능하다.
가변 길이 레코드를 저장하는 페이지는 빈 공간에 대한 세심한 관리가 필요하다. 빈 공간을 관리하는 방법 중 하나는 빈 공간의 시작점을 가리키는 포인터를 사용하는 것이다. 그러기 위해서는, 항상 레코드들이 빈 공간 없이 연속적으로 배치되어 있어야 한다는 것이다.

4.3. 레코드(Record)
중복 저장을 방지하기 위해, 레코드의 필드 수와 필드 타입 등의 기본 정보는 시스템 카탈로그(System Catalog)에 저장된다.
4.2.1. 고정 길이 레코드(fixed-length records)
각 필드의 길이와, 필드의 수 모두 고정되어 있다. 그렇기 때문에 레코드 주소가 주어진 경우, 특정 필드의 주소는 시스템 카탈로그에 저장된 필드 길이 정보를 활용해 파악할 수 있다.

4.2.2. 가변 길이 레코드(variable-length records)
관계형 모델에서는 모든 레코드의 필드 수가 고정되어 있으므로, 가변 길이 필드가 있을 때만 가변 길이 레코드가 된다.
가변 길이 레코드 포맷 유형:
1. 필드 구분자로 구분하여 연속적으로 저장하는 방식. 단점: 특정 필드를 찾으려면 레코드를 순차적으로 확인해야 한다.
2. 레코드 시작 부분에 정수값 오프셋 배열을 배치하는 방식. 이때, 배열의 i번째 정수는 i번째 필드의 시작 상대 주소를 의미하고, 마지막 필드가 끝나는 위치까지 저장한다. 만약, 필드 값이 null인 경우, 끝 지점 포인터를 시작 지점과 동일하게 설정한다.
- 장점: 직접 접근이 가능하고, null 값 처리가 가능하다.
- 단점: 1. 수정 시 크기가 증가하면 나머지 필드를 이동시켜야 한다. 2. 수정 시 크기가 가용 공간보다 크면 다른 페이지로 이동시켜야 한다. 이 경우 변경 rid 참조 문제가 발생할 수 있다. 3. 수정 시 레코드가 커져 어느 페이지와 맞지 않을 경우 분할해야 한다. 이때, 분할된 레코드는 체인으로 연결해야 한다.

'CS > DB' 카테고리의 다른 글
| [DB] 5. 트랜잭션(Transaction) (0) | 2024.12.15 |
|---|---|
| [DB] 4. 외부 정렬(External Sorting) (0) | 2024.12.14 |
| [DB] 3. 질의 수행(Query Evaluation) (2) | 2024.12.14 |
| [DB] 1. 인덱싱(Indexing) (0) | 2024.08.29 |