2025. 2. 28. 05:18ㆍML/NLP
이번 글에서는 DeepSeek-V3에서 사용된 방법론들에 대해 살펴볼 것이다.
DeepSeek-V3은 기존 트랜스포머 아키텍처와 두 가지 주요 부분에서 차이를 보인다.
1. Multi-Head Attention (MHA) → Multi-Head Latent Attention (MLA)
2. FeedForward Network (FFN) → Mixture of Experts (MoE) 기반 FeedForward Network (FFN)

1. Mutli-head Latent Attention (MLA)
최근 CoT, 추론 모델(reasoning model)의 등장 등 inference-time scaling 방법론이 각광 받으면서, 답변 길이가 길어지는 추세가 나타나 KV Cache가 점유하는 메모리 사용량이 늘어나고 있다.
이러한 메모리 효율성 문제를 해결하기 위해 다양한 방법론들이 활발히 연구되고 있다. 대표적으로, Meta에서 발표한 Grouped Query Attention (GQA)가 있다.
Grouped Query Attention (GQA)는 head 수에 비례하여 증가하는 KV Cache 크기 문제를 해결하기 위해, head 수만큼 KV를 생성하는 대신 여러 head가 KV를 공유하는 방식을 채택했다. 성능 저하는 불가피하지만 오버헤드 감소 효과가 더 크다고 판단해, 이를 감수하는 선택을 한 것 같다.

MLA도 head 수에 비례하여 증가하는 KV Cache 크기 문제를 해결하기 위해 연구된 방법론이다.
1.1. $\mathbf W_k^{(s)}$를 $\mathbf q_t^{(s)}$에 흡수시킨다. $\mathbf{q}_t^{(s)} \mathbf{k}_i^{(s)\top} = \left(\mathbf{h}_t \mathbf{W}_q^{(s)}\right) \left(\mathbf{h}_i \mathbf{W}_k^{(s)}\right)^\top = \left(\mathbf{h}_t \mathbf{W}_q^{(s)} \mathbf{W}_k^{(s)\top}\right) \mathbf{h}_i^\top$
기존에는 토큰 당 head 개수만큼의 key vector($\mathbf k_i^{(1)}, \mathbf k_i^{(2)}, \cdots, \mathbf k_i^{(h)}$)를 갖고 있어야 한다.
위와 같이 흡수하면 모든 head가 동일한 $\mathbf h_t$를 공유하기 때문에, 토큰 당 하나의 vector $\mathbf h_t$만 갖고 있어도 충분하다.
수식 해석:
1. hidden vector $\mathbf h_t$를 query vector $\mathbf q_t^{(s)}$로 변환하며, 벡터를 $\mathbb R^{d_h}$ 차원에서 $\mathbb R^{d_v}$ 차원으로 이동시켰다.
2. $\mathbf q_t^{(s)}$와 $\mathbf h_i$가 내적할 수 있게, $\mathbf W_k^{(s)\top}$를 활용해 원래 차원인 $\mathbb R^{d_h}$로 다시 돌아왔다. 이때, 내적값이 보존되도록 변환한다.
transpose matrix $\mathbf A^\top$ transforms a co-vector from the space of $\mathbf A \mathbf x$ back to space of $\mathbf x$ while retaining scalar value. (=즉, $\mathbf A^\top$는 $\mathbf{A} \mathbf{x}$가 속한 공간의 공벡터(Co-vector)를 원래 벡터 공간($\mathbf x$)으로 스칼라 값을 유지한 채 변환하는(=되돌리는) 역할을 한다.)
Co-vector는 벡터를 받아서 숫자를 반환하는 선형 함수이며, $\mathbf{\omega} = \begin{bmatrix} \omega_1 & \omega_2 & \omega_3 \end{bmatrix}$와 같이 행 벡터(row vector)로 표현한다.
($\mathbf x$ = $\mathbf h_i$, $\mathbf A$ = $\mathbf W_k^{(s)}$, $\mathbf{A} \mathbf{x}$가 속한 공간의 공벡터 = $\mathbf q_t^{(s)}$, 원래 벡터 공간($\mathbf x$)으로 이동한 공벡터 = $\mathbf q_t^{(s)} \mathbf W_k^{(s)\top}$, 선형 함수 = 내적)

1.2. How to Apply Rotary Positonal Encoding (RoPE) in MLA
현재 대부분의 LLM은 RoPE를 사용하여 토큰 간 위치 정보를 전달한다.
MLA에 RoPE을 사용하면 수식은 다음과 같아진다.
$$\mathbf{q}_t^{(s)} \mathbf{k}_i^{(s)\top} = \left( \mathbf{h}_t \mathbf{W}_q^{(s)} \mathcal{R}_t \right) \left( \mathbf{h}_i \mathbf{W}_k^{(s)} \mathcal{R}_i \right)^\top = \mathbf{h}_t \left( \mathbf{W}_q^{(s)} \mathcal{R}_{t-i} \mathbf{W}_k^{(s)\top} \right) \mathbf{h}_i^\top$$
이러면, $\mathbf q_t^{(s)}$가 토큰 간의 상대적 위치 정보인 $\mathcal{R}_{t-i}$까지 흡수하여 position dependent하게 된다.
이 방식은 저장해야 할 Query 벡터의 개수가 급격히 증가하여 메모리 효율성에 전혀 도움이 되지 않는다.
DeepSeek-V3의 저자들은 이를 해결하기 위해 위치 벡터를 추가하고, 이를 기존 Query와 Key에 결합(Concat)하는 방식으로 우회했다.
수식으로 표현하면 다음과 같다.
$$ \mathbf{q}_t^{(s)} = \begin{bmatrix} \mathbf{h}_t \mathbf{W}_{qh}^{(s)}, \quad \text{RoPE}\left(\mathbf{h}_t \mathbf{W}_{qr}^{(s)}\right) \end{bmatrix} \in \mathbb{R}^{d_k + d_r}, \\ \mathbf{k}_i^{(s)} = \begin{bmatrix} \mathbf{h}_i \mathbf{W}_{kh}^{(s)}, \quad \text{RoPE}\left(\mathbf{h}_i \mathbf{W}_{kr}\right) \end{bmatrix} \in \mathbb{R}^{d_k + d_r}$$
KV Cache를 줄이기 위해, Key는 모든 헤드가 동일한 위치 벡터를 공유하는 방식을 채택했다.
위치 정보는 헤드마다 다르더라도 동일하기 때문에 굳이 다르게 설정할 필요가 없어, 이러한 구조를 채택한 것으로 보인다.
hidden vector $\mathbf h_t$를 latent 차원 벡터인 cache vector $\mathbf c_t^{q}$와 $\mathbf c_t^{kv}$로 축소(compress)하여 KV Cache의 메모리 효율성을 더 높였다.
수식은 다음과 같이 변한다.
$$ \mathbf{c}_t^q = \mathbf{h}_t \mathbf{W}_{cq} \in \mathbb{R}^{d_c}, \quad \mathbf{W}_{cq} \in \mathbb{R}^{d \times d_c} \\ \mathbf{c}_i^{kv} = \mathbf{h}_i \mathbf{W}_{ckv} \in \mathbb{R}^{d_c}, \quad \mathbf{W}_{ckv} \in \mathbb{R}^{d \times d_c} \\ \mathbf{q}_t^{(s)} = \begin{bmatrix} \mathbf{c}_t^q \mathbf{W}_{qc}^{(s)}, \quad \text{RoPE}\left(\mathbf{c}_t^q \mathbf{W}_{qr}^{(s)}\right) \end{bmatrix} \in \mathbb{R}^{d_k + d_r}, \quad \mathbf{W}^{(s)}_{qc} \in \mathbb{R}^{d_c \times d_k}, \ \mathbf{W}^{(s)}_{qr} \in \mathbb{R}^{d_c \times d_r} \\ \mathbf{k}_i^{(s)} = \begin{bmatrix} \mathbf{c}_i^{kv} \mathbf{W}_{kc}^{(s)}, \quad \text{RoPE}\left(\mathbf{h}_i \mathbf{W}_{kr}\right) \end{bmatrix} \in \mathbb{R}^{d_k + d_r}, \quad \mathbf{W}^{(s)}_{kc} \in \mathbb{R}^{d_c \times d_k}, \ \mathbf{W}^{(s)}_{kr} \in \mathbb{R}^{d \times d_r}$$
결론: KV Cache는 어텐션 블록마다 토큰 당 cache vector $\mathbf c_i^{kv}$와 위치 벡터 $\text{RoPE}\left(\mathbf{h}_i \mathbf{W}_{kr}\right)$만 가지고 있으면 된다. 참고로, $\mathbf W_v^{(s)}$는 $\mathbf W_o$에 흡수된다.
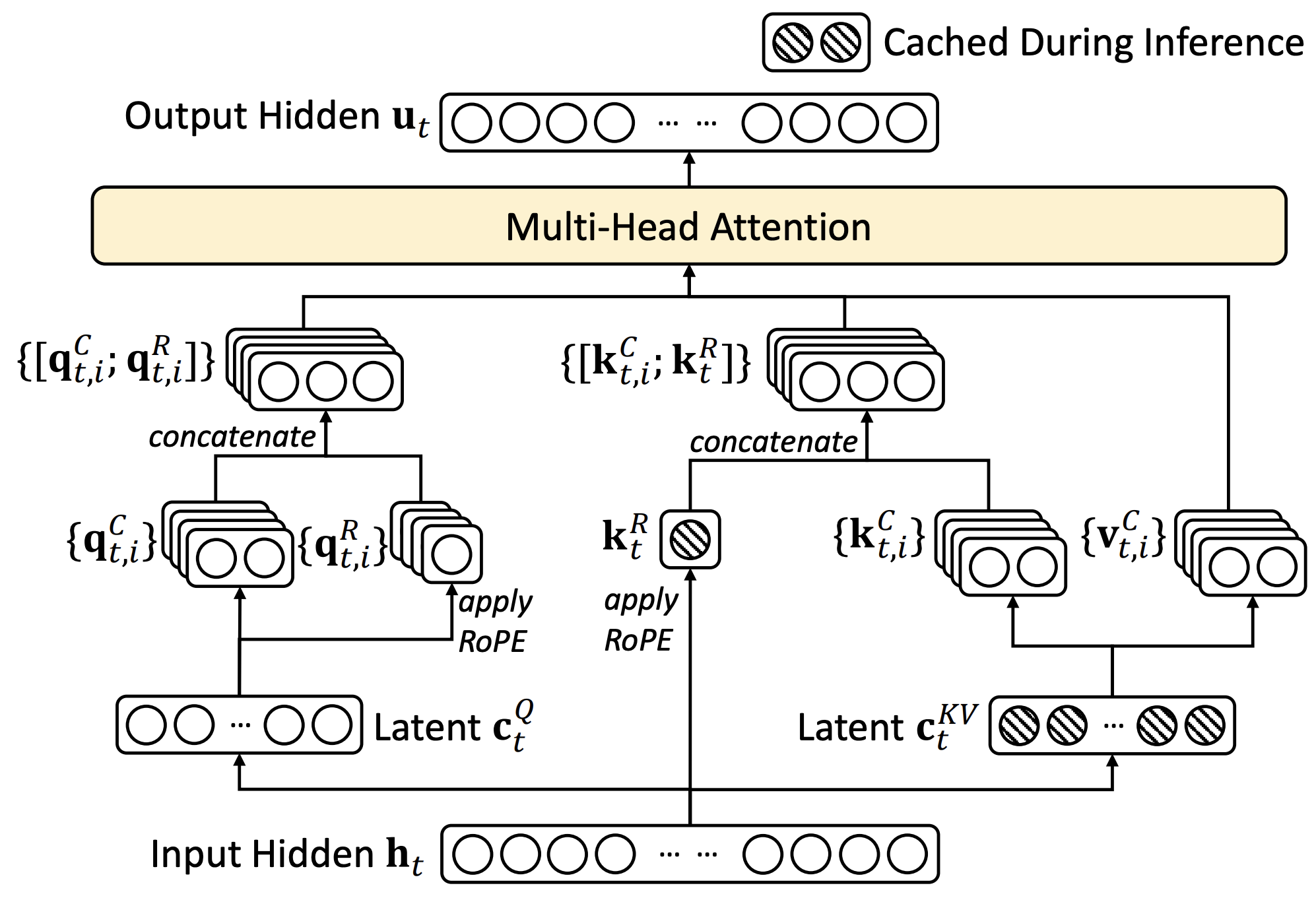
$$ \mathbf{c}_t^q = \mathbf{h}_t \mathbf{W}_{cq} \in \mathbb{R}^{d_c}, \quad \mathbf{W}_{cq} \in \mathbb{R}^{d \times d_c} \\ \mathbf{c}_i^{kv} = \mathbf{h}_i \mathbf{W}_{ckv} \in \mathbb{R}^{d_c}, \quad \mathbf{W}_{ckv} \in \mathbb{R}^{d \times d_c} \\ \mathbf{q}_t^{(s)} = \begin{bmatrix} \mathbf{c}_t^q \mathbf{W}_{qc}^{(s)} \mathbf{W}_{kc}^{(s)\top}, \quad \text{RoPE}\left(\mathbf{c}_t^q \mathbf{W}_{qr}^{(s)}\right) \end{bmatrix} \in \mathbb{R}^{d_c + d_r}, \quad \mathbf{W}^{(s)}_{qc} \in \mathbb{R}^{d_c \times d_k}, \ \mathbf{W}^{(s)\top}_{kc} \in \mathbb{R}^{d_k \times d_c}, \ \mathbf{W}^{(s)}_{qr} \in \mathbb{R}^{d_c \times d_r} \\ \mathbf{k}_i^{(s)} = \begin{bmatrix} \mathbf{c}_i^{kv}, \quad \text{RoPE}\left(\mathbf{h}_i \mathbf{W}_{kr}\right) \end{bmatrix} \in \mathbb{R}^{d_c + d_r}, \quad \mathbf{W}^{(s)}_{kr} \in \mathbb{R}^{d \times d_r}$$
$$\mathbf{o}_t^{(s)} = Attention \left( \mathbf{q}_t^{(s)}, \mathbf{k}_{\leq t}^{(s)}, \mathbf{c}_{\leq t}^{kv} \right) \triangleq \frac{\sum_{i \leq t} \exp \left( \mathbf{q}_t^{(s)} \mathbf{k}_i^{(s)\top} \right) \mathbf{c}_i^{kv}} {\sum_{i \leq t} \exp \left( \mathbf{q}_t^{(s)} \mathbf{k}_i^{(s)\top} \right)}$$
$$ \mathbf{o}_t = \begin{bmatrix} \mathbf{o}_t^{(1)}, \mathbf{o}_t^{(2)}, \dots, \mathbf{o}_t^{(h)} \end{bmatrix} \in \mathbb{R}^{h*d_c} \\ \mathbf{W}_o = \begin{bmatrix} \mathbf{W}_v^{(1)} \mathbf{W}_o^{(1)} \\ \mathbf{W}_v^{(2)} \mathbf{W}_o^{(2)} \\ \vdots \\ \mathbf{W}_v^{(h)} \mathbf{W}_o^{(h)} \end{bmatrix} \in \mathbb{R}^{h*d_c \times d}, \quad \mathbf{W}_v^{(s)} \in \mathbb{R}^{d_c \times d_v}, \ \mathbf{W}_o^{(s)} \in \mathbb{R}^{d_v \times d} \\ \mathbf H_t = \mathbf o_t \mathbf W_o \in \mathbb{R}^{d}$$
2. DeepSeekMoE
DeepSeek-V3은 MoE 구조의 FFN을 사용하고 있다.
구체적으로는, $N_s$개의 FFN은 고정적으로 사용하고, 추가적으로 라우터가 $K_r$개의 FFN 중에서 $N_t$개를 선택하여 사용한다.
DeepSeekMoE 순서도

$$s_{i,t} = \text{Sigmoid} \left( \mathbf{u}_t^T \mathbf{e}_i \right), \quad (\mathbf u_t: \text{hidden vector}, \mathbf e_i : \text{decision vector of i-th expert}) \\ g_{i,t} = \frac{g'_{i,t}}{\sum_{j=1}^{N_r} g'_{j,t}}, \quad g'_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}, \end{cases} \\ \mathbf{h}'_t = \mathbf{u}_t + \sum_{i=1}^{N_s} \text{FFN}_i^{(s)} (\mathbf{u}_t) + \sum_{i=1}^{N_r} g_{i,t} \text{FFN}_i^{(r)} (\mathbf{u}_t)$$
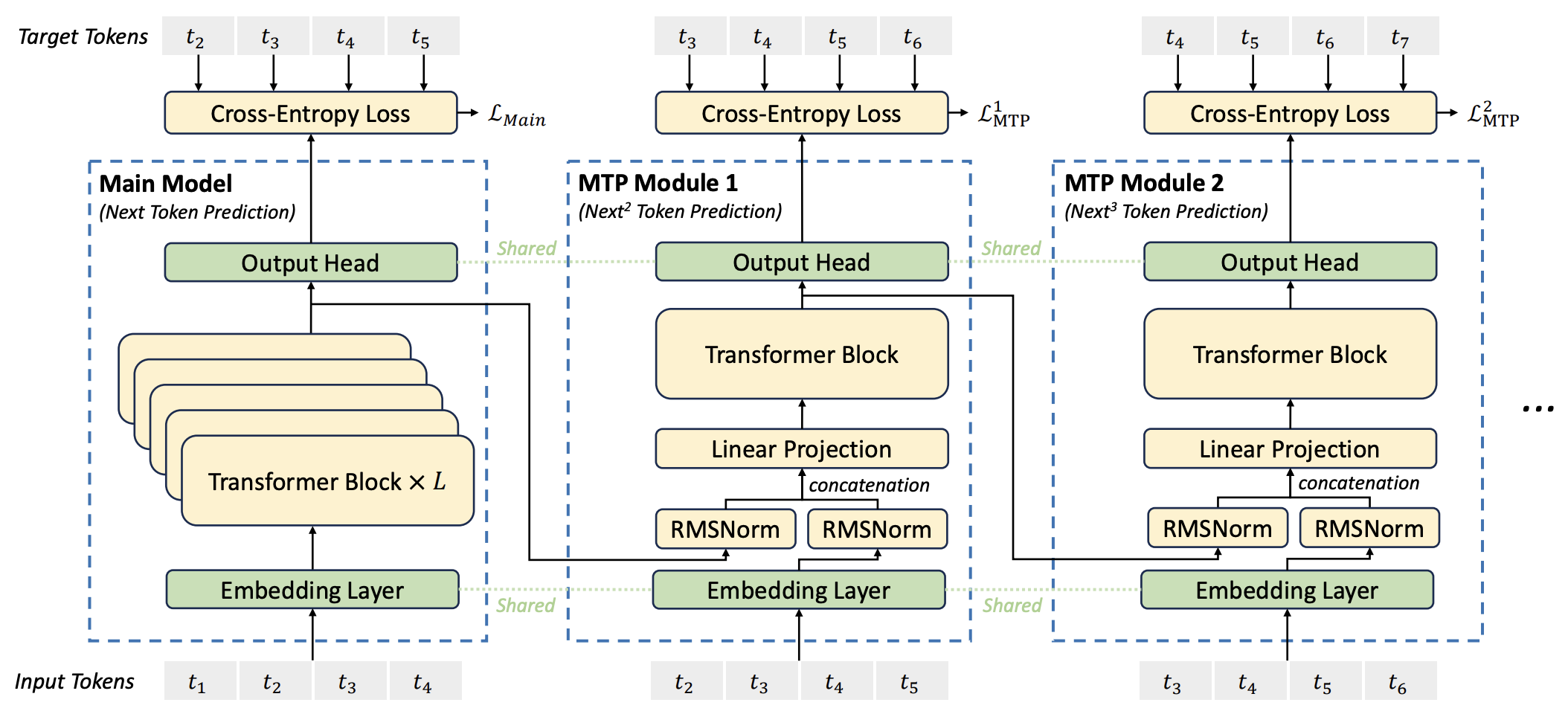
3. Multi-Token Prediction Objective
DeepSeek-V3는 hidden vector $\mathbf h_t$으로 $\mathbf x_{t+1}$을 예측하는 데 사용함과 동시에 $x_{>t+1}$을 예측하는 데 사용한다.
구체적으로 말하면, $\mathbf h_t$와 $\mathbf x_{t+1}$의 임베딩 벡터를 concat한 후, 단일 트렌스포머 블록만 사용해 $\mathbf x_{t+2}$를 예측하는 방식으로 추가 학습이 진행된다.
직관적으로 말하면, $\mathbf h_t$가 $\mathbf x_{t+1}$뿐만 아니라 $x_{>t+1}$도 맞출 수 있게 표현(representation)을 잘 담고 있도록 학습을 유도한다.
이는 hidden vector $\mathbf h_t$가 $\mathbf x_{t+1}$을 예측할 때, 이후 문맥인 $\mathbf x_{>t+1}$도 고려하도록 유도하여, 더 일관성 있고 맥락에 맞는 텍스트를 생성하는 데 도움을 줄 수 있다.
'ML > NLP' 카테고리의 다른 글
| [LLM 시간 및 메모리 최적화] 2. KV Cache & Paged Attention (0) | 2025.02.26 |
|---|---|
| [LLM 시간 및 메모리 최적화] 1. Flash Attention (0) | 2025.02.24 |
| [NLP] Transformer (2) | 2024.08.19 |
| [NLP] RNN, LSTM, Attention (0) | 2024.03.31 |