2024. 3. 11. 21:46ㆍML/DL
이번 글에서는 딥러닝이 어떤 방식으로 문제를 접근하고 푸는지에 대해 자세히 살펴볼 것이다.
더 나아가, 딥러닝에 근간이 되는 이론이 무엇인지 살펴볼 것이다.
이진 분류 문제 풀이 방법
"임의의 키와 몸무게가 주어졌을 때 다이어트가 필요한지 혹은 필요하지 않은지를 판단"하는 문제를 풀어볼 것이다.
우선, 문제를 풀기 위해서는 문제를 정확히 이해하고, 이를 (수학적으로) 적절하게 재정의해야 한다.
위 문제를 독립 변수인 키/몸무게(=
입력이 키/몸무게고 출력이 다이어트의 필요성 (or 확률)인 모델 (or 알고리즘)을 만든 후,
모델 출력인
모델 추정 (DNN)
딥러닝으로 문제를 풀 때는 그에 맞는 적절한 DNN 구조를 설계하여 모델을 추정한다.
activation function: unit step function
(분류 기준선(경계선=
활성화 함수가 계단 함수인 1층 (인공) 신경망 즉, 1층 퍼셉트론으로 입출력 간의 관계를 표현해볼 수 있다.
이를 3D로 표현하면 다음과 같다.
분류 기준선(회색 부분)은 선형이지만, 입출력(

하지만, 위 방식은 여러 문제점이 존재한다.
1. 분류 경계선에서 미분이 불가능해 최적화 기법 중 하나인 경사 하강법을 사용하지 못한다.
2. 경계선 기준으로 값(
경계선을 살짝 넘었다고 확률이 0에서 1로 급변하는 것은 부자연스럽다.
activation function: sigmoid function
unit step function의 문제점을 어느 정도 해소하기 위해,
활성화 함수를 보다 부드러운 sigmoid 함수(
이를 3D로 표현하면 다음과 같다.
위와 마찬가지로, 분류 기준선은 선형이고, 입출력(
하지만 위와 다르게, sigmoid 함수를 활성화 함수로 사용하면,
1. 전구간에서 미분이 가능하다. (참고로, sigmoid 함수의 최대 기울기는 1/4이다.)
2. 경계선 기준으로 값이 보다 부드럽게 변한다.
더 중요한 것은 unit step function보다 합리적인 분류 기준선을 찾게 된다.
판단 기준 (손실 함수)
지금까지 문제에 맞게 DNN 구조를 설계해 모델을 추정했다. 이제부터는 데이터 기반
딥러닝은 경사 하강법 (e.g., SGD, Adam)으로 손실값이 최소가 되는 최적의 파라미터 조합을 찾기 때문에, 판단 기준인 "손실 함수"만 문제에 맞게 잘 정의하면 된다.
그럼 이제부터 손실 함수를 정의해보겠다.
sigmoid 함수를 활성화 함수로 사용한 경우
모델은
이를 더 직관적으로 바꾸면 다음과 같다.
즉,
각각의 데이터
하지만, 1보다 작은 값을 계속 곱하면 결국 0에 가까워지며, 이를 컴퓨터로 계산하면 underflow 문제가 발생한다.
그렇기 때문에,
(단조 증가(monotonic increase)하기 때문에 바꿔도 가능하다.
쉽게 말해, 한쪽이 작아지면 다른쪽도 반드시 작아지고 한쪽이 커지면 다른쪽도 반드시 커지기 때문이다.)
ML에서는 일반적으로 값이 낮을수록 좋은 "손실 함수"를 판단 기준으로 사용하기 때문에, 위 수식에 -를 곱해 손실 함수로 사용할 것이며, 이를 Binary Cross Entropy라고 부른다.
logistic regression
위 방식으로 이진 분류하는 것을 logistic regression이라고 한다.
"logit(=log-odd)인
모델이 logit
즉, 분류 문제를 regression 문제로 바꿔 풀었다고 볼 수 있다. (regression에 대한 자세한 내용은 [ML] 2. Linear Regression에서)
참고로, odds는 "승산"을 의미한다. 승산이란 "어떤 사건이 발생할 확률(=
sigmoid 함수의 진정한 의미
logit
위에서 알 수 있듯이, logit
그래서, 이진 분류(YES/NO) 모델의 (마지막) 출력층 활성화 함수로 sigmoid 함수를 사용하는 것이다.
MSE(Mean Square Error) vs BCE(Binary Cross Entropy)
MSE를 이진 분류 손실 함수로 사용하면, BCE와 무엇이 다른지 살펴볼 것이다.
이진 분류의 MSE와 BCE은 각각
민감도
위 수식을 조건문으로 풀어쓰면 다음과 같다.
이를 그래프로 표현하면 다음과 같다.
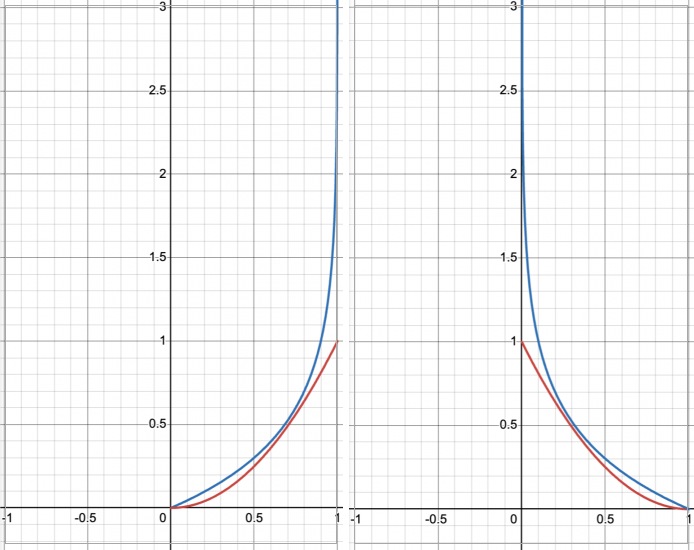
위 그래프에서 알 수 있을듯이, BCE(파란선)가 error에 훨씬 더 민감하다.
convex vs non-convex
출력층 파라미터 loss landscape의 개형이 MSE이면 non-convex, BCE이면 convex다.
이를 수식과 그래프로 표현하면 다음과 같다.


위 그래프를 보면 알 수 있듯이, BCE는 어느 지점에서 시작해도 학습이 이루어진다. 즉, 최솟값으로 이동한다.
반면, MSE는 x, y 모두 큰 음수에서 시작하면 학습이 이루어지지 않는다. 즉, 최솟값으로 이동하지 않는다.
non-convexity
파라미터 loss landscape의 non-convexity가 MSE이면 높아지고, BCE이면 낮아진다.
당연하게도, 출력층으로부터 멀어질수록 non-convexity는 심해진다.
하지만, 출력층이 convex면 non-convexity가 덜 심해지기 때문이다.
위 내용을 표로 정리하면 다음과 같다.
| Binary Cross Entropy |
Mean Squre Error |
||||||
| 민감도 | 높다 | 낮다 | |||||
| 출력층 loss landscape의 개형 | convex | non-convex | |||||
| 은닉층의 non-convexity |
낮다 | 높다 | |||||
결론, 모든 면을 봤을 때 이진 분류에서는 BCE를 손실함수로 사용하는 것이 유리하다.
어떤 손실 함수를 사용할지는 선택의 영역이다.
하지만, 어떤 것을 선택하느냐에 따라 학습 난이도가 달라지기 때문에, 문제에 맞는 손실 함수를 선정해야 한다.
What is convex function?
convex 함수의 정의는 다음과 같고, 이를 만족하지 않은 함수를 non-convex 함수라고 부른다.
쉽게 말해, convex 함수는 볼록 함수다.
그렇기 때문에, 경사 하강법에서 convex 함수가 유리하다. 어느 지점에서 시작해도 최솟값으로 수렴하기 때문이다.
반대로, non-convex 함수는 극솟값에 갇힐 수 있기 때문에 불리하다.
☆ DL Estimates pY|X
우리가 궁극적으로 알고자 하는 것은 "임의의
1. 문제가 주는 정보 혹은 관찰을 통해 얻은 정보
2. 가설로 세운 분포의 모수(e.g., 베르누이 분포의 모수는
이때,
(
그렇기 때문에, 모수를 알기 위해서는
관계를 파악하는 방법은 다음과 같다.
1. 모수와
2. 가설로 세운
딥러닝은
이를 수식으로 표현하면 다음과 같다.
위 수식은 "모수가
일반적으로, 이렇게 추정한
결론, 딥러닝은 인공 신경망으로 구성된 MLE 기계다.
Exmple
분포
분포
이를 각각 NLL(Negative Log Likelihood function)로 바꾸면,
이는 앞에서 살펴본 대표적인 손실 함수 BCE와 MSE다.
즉, 손실함수는
그러므로, "문제에 맞는 손실 함수를 찾는 과정"은 "문제 상황에 맞는
이진 분류에는 확률변수
반대로, 회귀 문제에서는 확률 변수
다중 분류 문제 풀이 방법
"임의의 키와 몸무게가 주어졌을 때 어떤 체중상태(과체중, 정상체중, 저체중)인지를 판단"하는 문제를 풀어볼 것이다.
이진 분류와 마찬가지로, 문제를 풀기 위해서는 문제를 정확히 이해하고, 이를 (수학적으로) 적절하게 재정의해야 한다.
위 문제를 독립 변수인 키/몸무게(=
입력이 키/몸무게고 출력이 체중 상태의 확률분포(과체중/정상체중/저체중)인 모델 (or 알고리즘)을 만든 후,
모델 출력인
참고로,
모델 추정 (DNN)
딥러닝으로 문제를 풀 때는 그에 맞는 적절한 DNN 구조를 설계하여 모델을 추정한다.
activation function: softmax function
이진 분류와는 다르게 다중 분류에서는 출력층 노드 수를 범주(=class) 수 만큼 늘려야 한다.
그리고, 확률분포가 출력될 수 있도록 출력층의 활성화 함수로 softmax 함수
이진 분류 때와 동일하게, 1층 (인공) 신경망으로 입출력 관계를 표현하면 다음과 같다.
Why not
확률분포가 되기 위해서는 두 가지 조건을 충족해야 한다.
첫번째, 모든 출력값이 0보다 크거나 같아야 한다. 두번째, 출력값의 합이 1이어야 한다.
하지만, 위 함수는 입력값으로 1, 1, 1과 1, -1, 1이 들어왔을 때 이를 구분하지 못한다. 즉, 의미가 중복되는 영역이 많다. 다시 말해, 활용하지 못하는 영역이 많다.
반대로, softmax 함수는 입력마다 다른 값을 출력한다. 즉, 각 영역은 서로 다른 의미를 가지고 있다. 다시 말해, 모든 영역을 활용한다.
softmax vs sigmoid
softmax는 출력값을 묶어서 하나의 확률분포(
그렇기 때문에, softmax의 경우 임의의 출력값이 증가하면 필연적으로 다른 출력값이 감소하는 반면, sigmoid의 경우 임의의 출력값이 다른 출력값에 영향을 주지 않는다.
쉽게 말해, 다중 분류에서 sigmoid 함수를 사용하는 것은 "m개의 이진 분류 모델이 각 class가 나올 확률을 출력하는 방식"이다.
그렇기 때문에, softmax 함수가 multi-classification 문제에 더 적합하고, sigmoid 함수는 multi-label classification에 적합한 것이다.
판단 기준 (손실 함수)
모델 출력을 각 class의 확률로 정의했기 때문에,
(
softmax 함수를 활성화 함수로 사용한 경우
모델은
이를 더 직관적으로 바꾸면 다음과 같다.
이 수식에
정보 이론 관점
손실 함수가 cross-entropy이면, cross-entropy가 최소화하는 방향으로 학습이 진행된다.
위 수식처럼 cross-entropy는 무조건 entropy 보다 크기 때문에,
"cross-entropy를 줄인다"는 것은 "cross-entropy를 entropy에 점점 가깝게 만든다"는 것을 의미이다.
"cross-entropy가 entropy에 점점 가까워진다"는 것은 "분포 p가 분포 y에 점점 가까워짐"을 의미한다.
결론, "cross-entropy를 손실 함수로 삼았다"는 것은 "분포 p를 열심히 바꿔 분포 y와 같도록 하겠다"는 의도가 있다.
cross-entropy를 다중 분류 손실 함수로 사용하면, cross-entropy와 entropy의 관계는 다음과 같다.
즉, 나머지
이것만으로도 분포 p를 분포 y에 가깝게 만들 수 있다.
다중 분류도 MLE다
다중 분류는 분포
분포
이를 NLL로 바꾸면,
softmax regression
위 방식으로 다중 분류하는 것을 softmax regression이라고 한다.
"logit(=log-odds)인
모델이 logit
즉, 다중 분류 문제도 regression 문제로 바꿔 풀었다고 볼 수 있다. (regression에 대한 자세한 내용은 [ML] 2. Linear Regression에서)
참고로, 다중 분류에서의 odd는 "
softmax 함수의 진정한 의미
logit
위에서 알 수 있듯이, 다중 분류에서 logit
그래서, 다중 분류 모델의 (마지막) 출력층 활성화 함수로 softmax 함수를 사용하는 것이다.
'ML > DL' 카테고리의 다른 글
| [DL] 6.1. Batch Normalization (0) | 2024.03.22 |
|---|---|
| [DL] 6. 인공 신경망이 깊어질 때 발생하는 고질적 문제 (gradient vanishing & overfitting) (0) | 2024.03.19 |
| [DL] 5.3. hyper-parameter 선정 방법: validation loss (0) | 2024.03.10 |
| [DL] 5.2. Optimizer hyper-parameter: batch size & learning rate (0) | 2024.02.27 |
| [DL] 5.1. Model hyper-parameter: Weight initialization (0) | 2024.02.18 |