2024. 2. 27. 16:05ㆍML/DL
이번 장에서는 optimizer의 대표적인 hyper-parameter인 batch size와 learning rate에 대해 알아볼 것이다.
그 전에 학습에 대해 간단히 살펴보도록 하자.
딥러닝에서 학습은 "경사하강법으로 최적의 매개변수 즉, 손실 함수의 미분값이 0이 되는 지점을 찾는 과정"이며, 이는 파라미터 갱신을 통해 이루어진다.
파라미터를 갱신할 때는 어느 방향으로 얼마만큼 이동할지를 정해야 한다. 즉, 방향과 크기를 정해야 한다.
이것을 결정하는 대표적인 요소 두 가지가 바로 기울기(=gradient)와 학습률(=learning rate)이다.
방향은 기울기에 의해 결정되고, 크기(=보폭)는 기울기와 학습률에 의해 결정된다.
Batch size (방향)
탐험
쉽게 생각해 봤을 때, 배치 크기(=batch size)가 크면 정확하게 학습 데이터의 loss landscape를 추정하기 때문에 각각의 파라미터 갱신이 효율적일 것이다. 반대로, 배치 크기가 작으면 학습 데이터의 loss landscape를 부정확하게 추정하기 때문에 각각의 파라미터 갱신이 비효율적일 것이다.

하지만, 이는 1). 풀고자 하는 문제가 convex고 2). 일반화를 고려하지 않을 때만 유효한 것이다.
머신러닝으로 풀고자 하는 대부분의 문제는 non-convex이고, 일반화를 고려해야 한다.
그렇기 때문에, 모델 성능 측면(정확도+일반화)으로만 봤을 때 배치 크기를 늘린다고 무조건 좋은 것은 아니다.
위 그림처럼, LB(=large batch size)는 상대적으로 정확한 기울기를 찾아주고,
SB(=small batch size)는 상대적으로 부정확한 기울기를 찾아준다.
(참고로, 여기서 말하는 "기울기의 정확성"은 "전체 학습 데이터의 loss landscape과의 유사도"를 의미하는 것이다.)
이는 "LB가 제시한 방향은 노이즈가 작고, SB가 제시한 방향은 노이즈가 큼"을 의미한다.
방향에 노이즈가 크면, 탐험(=explore)을 장려하기 때문에 극솟값을 수월하게 벗어난다.
반면, 노이즈가 작으면, 탐험을 억제하기 때문에 극솟값을 벗어나기 어렵다.
학습 횟수 (or epoch 당 이동 거리)
기울기는 방향 뿐만 아니라 크기(=보폭 or 경사)도 가지고 있다.
다시 말해, 파라미터 갱신의 방향 뿐만 아니라 보폭도 어떤 배치를 가지느냐에 따라 달라진다.
하지만, 배치 크기에 따라 "기울기 방향과 크기의 확률분포"가 어떻게 바뀌는지 알 수 없다.
(알기 위해서는, 각 배치 크기에서의 loss landscape를 알아야 한다.)
그렇기 때문에, 어떤 배치 크기를 사용하던 동일한 확률분포를 가진다고 가정하는게 현재로써는 최선이다.
하지만 배치 크기로 epoch 당 step 횟수는 파악할 수 있다.
배치 크기가 커질수록 epoch 당 step 횟수가 줄어들고, 배치 크기가 작아질수록 학습 횟수가 늘어난다.
그렇기 때문에, 만약 LB와 SB의 기울기 방향과 크기의 확률분포가 동일하다고 가정했을 때,
LB는 학습 횟수가 줄어들어, epoch 당 이동 거리가 줄어든다.
반면, SB는 학습 횟수가 늘어 epoch 당 이동 거리가 증가한다.
Learning rate (크기, 보폭)
학습률(=learning rate)은 배치 크기와 다르게 보폭을 직접적으로 조절할 수 있는 대표적인 hyper-parameter다.
보폭 (or 이동 거리)
학습률을 높이면 보폭이 넓어져 학습을 빨리 마칠 수 있다.
반면, 학습률이 낮추면 보폭이 좁아져 학습을 늦게 마칠 수 있다.
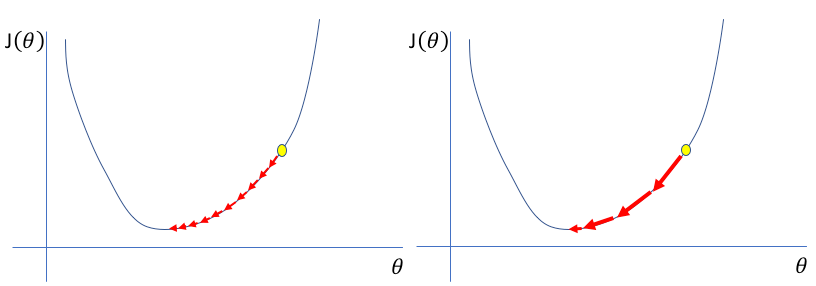
탐험
하지만 아래 그림처럼, 보폭을 넓히면 손실값이 발산해 학습이 이뤄지지 않을 수 있다.
그렇기 때문에, 보폭을 좁혀 학습하는게 느리지만 확실한 방법일 수 있다.

하지만, 이 또한 풀고자 하는 문제가 convex일 때만 유효한 것이다.

위 그림처럼, 보폭이 넓으면 극솟값을 벗어나기 쉬워지고, 보폭이 좁으면 극솟값을 벗어나기 어려워진다.
이를 다른 말로, "학습률이 높으면, 탐험을 장려하고, 학습률이 낮으면 탐험을 억제한다"고 말할 수 있다.
step 횟수 및 학습률과 $\lVert W_t - W_0 \rVert$ 간의 관계
아래 두 그래프는 Train longer, generalize better: closing the generalization gap in large batch training of neural networks 논문에서 배치 크기와 학습률에 관해 실험한 결과다.
왼쪽 그래프는 서로 다른 배치 크기에 동일한 학습률을 적용할 때 $\lVert W_t - W_0 \rVert$가 어떻게 변하는지를 표현한 것이고,
오른쪽 그래프는 배치 크기가 $M$이라고 할 때 학습률을 $\sqrt M$으로 적용할 때 $\lVert W_t - W_0 \rVert$가 어떻게 변하는지를 표현한 것이다.
학습률을 높이면 보폭(=step 당 이동 거리)이 증가함에 따라, 자연스럽게도 "step 당 $\lVert W_t - W_0 \rVert$ 증가량"도 증가함을 그래프로 확인할 수 있다.
(참고로, 대부분의 경우 "step 당 $\lVert W_t - W_0 \rVert$ 증가량"은 $\log t$에서 크게 벗어나지 않음을 확인할 수 있다.)

하지만, 학습률을 배치 크기에 비례하기 높였다 하더라도 학습 횟수가 낮기 때문에 탐험 범위는 작은 배치 크기에 한참 못 미친다.
그렇기 때문에, 만약 큰 배치 크기로 학습을 진행할 때 학습률을 높였는데도 일반화가 안되면, 학습 횟수를 늘려 탐험 범위를 높여 완만한 분지를 찾아보자.
참고로, Train longer, generalize better: closing the generalization gap in large batch training of neural networks 논문에서는 학습률 증가와 Ghost Batch Normalization을 사용하고 학습 횟수를 증가시켜 일반화시켰다.
더 나아가, 배치 크기에서의 탐험과 학습률에서의 탐험은 약간 다른 성질을 가지고 있다.
배치 크기에서의 탐험은 다양한 방향으로 탐험을 장려하는 방식이고,
학습률에서의 탐험은 탐험의 이동 거리를 증가시키는 방식이다.
결론, 1). 배치 크기를 줄이면, 탐험을 장려하고, epoch 당 학습 횟수도 증가한다.
2). 배치 크기를 높이면, 탐험을 억제하고, epoch 당 학습 횟수도 감소한다.
3). 학습률을 높이면, 탐험을 장려하고, 보폭(=학습량)도 넓어진다.
4). 학습률을 줄이면, 탐험을 억제하고, 보폭(=학습량)도 좁아진다.
위 그래프에서 봤듯이, 학습 횟수 많아지거나 보폭이 넓어지면 자연스럽게 $\lVert W_t - W_0 \rVert$도 증가한다.
(주의: 탐험 자유도를 너무 많이 부여하면 학습이 진행되지 않을 수 있다.)
우리는 크게 두 가지 기준(깊은/얕은, 완만한/가파른)으로 극솟값을 4가지 종류로 분류할 수 있다.
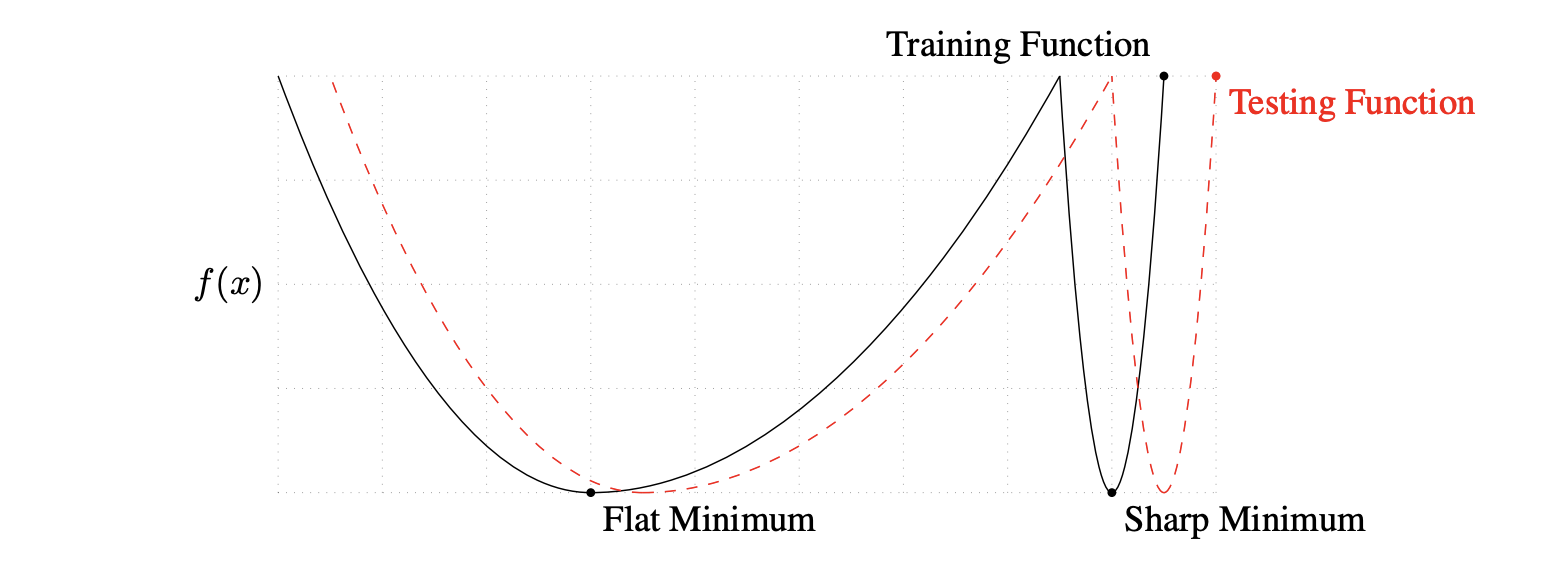
깊은 극솟값과 얕은 극솟값은 성능(=performance)와 연관이 있다. 손실값이 낮을수록 극솟값의 깊이가 깊기 때문이다.
완만한 극솟값과 가파른 극솟값은 일반화(=generalization)과 연관이 있다.
아래 그림과 같이 training function(=train loss landscape)와 testing function(=test loss landscape)간의 차이가 발생하면, 가파른 극솟값의 함수값 차이는 큰 반면, 완만한 극솟값의 함수값 차이는 작기 때문이다.
탐험을 억제/장려하면 어떤 극솟값에 갇히는지 살펴보도록 하자.
우선 탐험을 장려하면 웬만한 노이즈도 탈출할 수 없는 완만한 분지의 극솟값에 수렴할 확률이 높다.
그리고, 완만한 분지의 극솟값이기 때문에, 초깃값($w_0$)과의 거리가 멀 것이다.
반면, 탐험을 억제하면, 처음으로 만나는 극솟값에 갇힐 확률이 높다. 즉, 초깃값과 가장 가까운 극솟값에 갇힐 확률이 높다.
갇힐 곳이 완만한 분지의 초깃값일지 가파른 골짜기의 초깃값일지는 모른다.
하지만, 앞에서 말한거처럼, 완만한 분지의 초깃값은 거리가 멀기 때문에 완만한 분지의 초깃값에 도달하기 전, 가파른 골짜기의 극솟값에 빠질 확률이 높다.
결론, 탐험을 장려하면 초깃값과 거리가 먼 완만한 분지의 극솟값에 수렴할 확률이 높다.
반면, 탐험을 억제하면 초깃값과 거리가 가까운 가파른 골짜기의 극솟값에 빠질 확률이 높다.
ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA 논문도 아래와 같은 실험 결과를 바탕으로 비슷한 주장을 펼치고 있다.
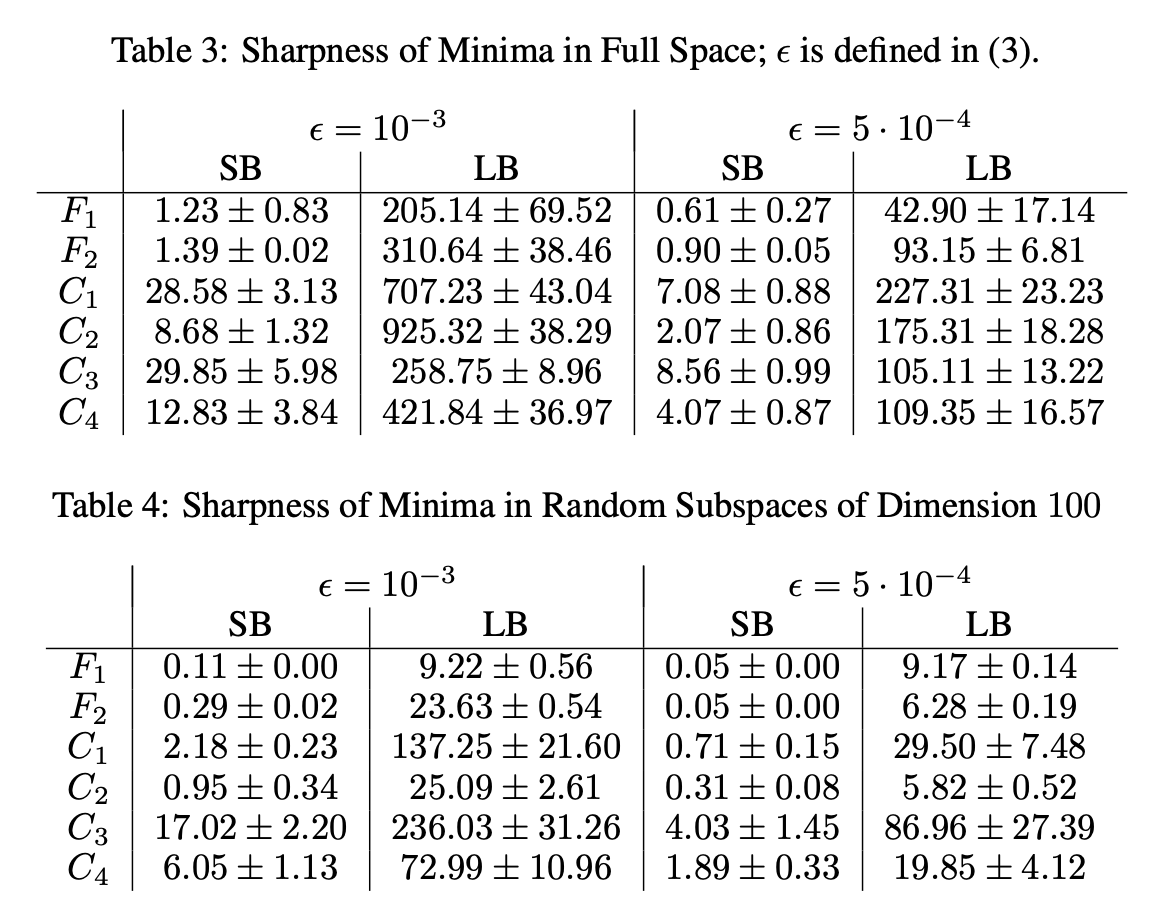
LB 학습으로 얻은 매개변수가 $x_l^*$고, SB 학습으로 얻은 매개변수가 $x_s^*$라고 할 때,
$x_l^*$의 손실값인 $f(x_l^*)$ 즉, $x_l^*$의 고도는 주위보다 훨씬 낮다.
반면에, $x_s^*$의 손실값인 $f(x_s^*)$ 즉, $x_l^*$의 고도는 $x_l^*$ 주위와 비슷하다.
결론, LB는 완만한 분지의 극솟값에 수렴하고, SB는 가파른 골짜기의 극솟값에 수렴한다.
batch size & learning rate 설정 방법 노하우
1. Linear Scaling Rule
배치 크기를 증가시키면, epoch 당 step 횟수를 줄여 학습 시간을 단축시킬 수 있다.
하지만, 학습 횟수가 줄어들 뿐만 아니라 탐험이 억제되어, 학습이 진행되지 않거나 일반화가 잘 이루어지지 않는다.
이때, 학습률을 높여 보폭을 넓히고, 탐험을 장려해 위 문제를 해결한다.
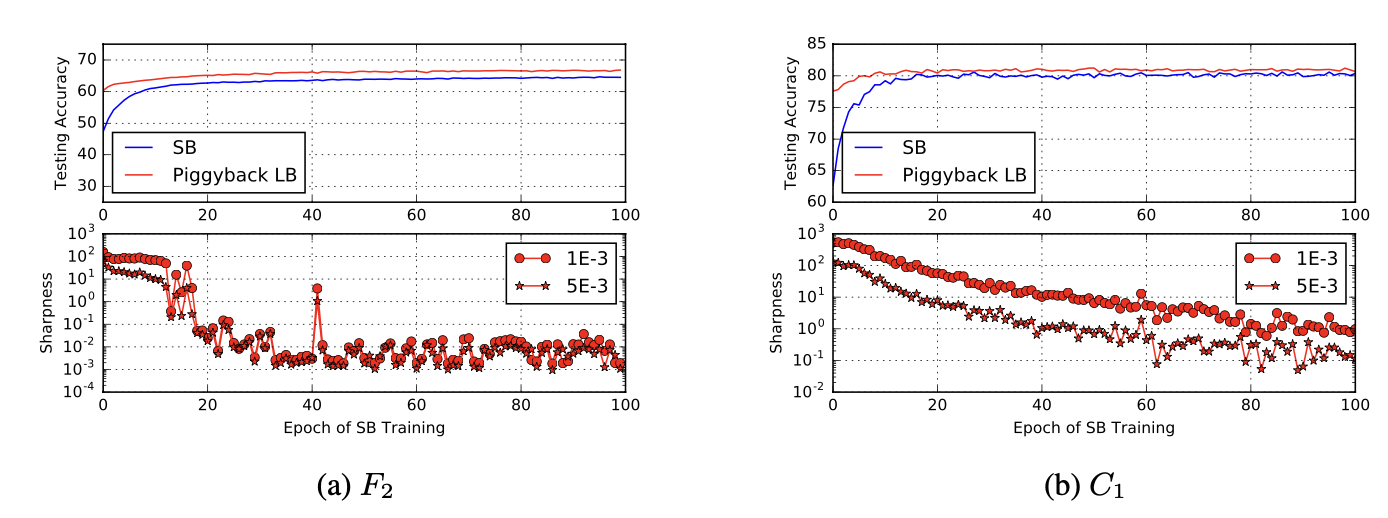
2. expand BS
학습 초기에 배치 크기를 낮춰 탐험을 장려해 평평한 분지를 찾게 한다.
이후, 배치 크기를 높여, 안전하게 평평한 분지의 극솟값에 수렴하도록 한다.
아래 그래프는 ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA 논문에서 위 방식대로 실험한 결과다.
3. expand BS & decay LR
학습 초기에 배치 크기를 낮추고 학습률을 높여 학습량을 높일 뿐만 아니라, 탐험 자유도를 최대한 높혀 평평한 분지를 찾도록 한다.
이후, 배치 크기를 높이고, 학습률을 낮춰 탐험을 억제해 안전하게 극솟값을 찾도록 유도한다.
(참고로, 언어 모델 크기가 커질수록 배치 크기는 늘리고 max lr는 줄인다. WHY?)
'ML > DL' 카테고리의 다른 글
| [DL] 7. How does DL solve problems? (0) | 2024.03.11 |
|---|---|
| [DL] 5.3. hyper-parameter 선정 방법: validation loss (0) | 2024.03.10 |
| [DL] 5.1. Model hyper-parameter: Weight initialization (0) | 2024.02.18 |
| [DL] 4. Backpropagation (0) | 2024.02.13 |
| [DL] 3.1. Advanced Optimization (Momentum, RMSprop, Adam) (0) | 2024.02.13 |