2022. 10. 26. 13:33ㆍPaper Review
Abstract
이번 연구에서는, "언어 모델 확장이 모든 task의 few-shot 성능을 크게 향상시킴"을 보여준다. 그 중 몇 가지 task는 이전 state-of-the-art를 능가하는 성능을 보여준다.
GPT-3는 parameter 수정 및 fine-tuning을 하지 않고, 오직 텍스트(=입력 토큰)로 제공된 task 설명 및 시연(=예시 지문(or 보기)와 정답)만으로 모든 task를 수행한다.
Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine tuning approaches.
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
1. Introduction
최근 pre-trained 언어 모델은 구조 변경 없이 fine-tuning을 진행한다.
위 기법(=pre-training & fine-tuning 기법)은 task별 모델 구조 변경을 하지 않다 보니, 보다 간편히 task를 학습시킬 수 있다.
하지만, 아직도 task별 dataset 수집과 fine-tuning 과정(=추가적인 학습)이 필요하다.
위 한계점은 여러 가지 이유로 해소돼야 한다.
1. task를 학습시키기 위해서는, 라벨링된 수 만개의 dataset이 필요하다. 때문에, dataset 수집이 어려운 task는 학습이 매우 힘들다.
2. 모델 표현력이 커질수록 또는 학습 분포가 좁을수록, dataset의 허위 관계를 학습할 가능성이 매우 높아진다.
위 문제는 pre-training & fine-tuning 기법에 치명적이다. 크기가 큰 모델이 많은 정보를 흡수(=pre-training)한 후, 상대적으로 좁은 분포를 학습(=fine-tuning)을 하기 때문이다.
뿐만 아니라, 이전 연구에서 "모델 크기 확장이 OOD 일반화에 도움 되지 않음"을 관찰했다. 즉, 크기가 큰 모델이 학습 분포를 매우 구체적으로 학습하여 OOD 일반화가 잘 이루어지지 않는다. 이는 "pre-training & fine-tuning 기법에는 OOD 일반화가 좋지 않음"을 시사한다. (필자는 위 2가지 문제가 dataset의 과적합 때문에 발생한다고 생각한다.)
3. 사람은 task를 학습할 때 수 만개의 dataset이 필요하지 않다. 오직 간단한 지시문(=task 설명) 혹은 몇 개의 시연이면 충분하다.
recently pre-trained recurrent or transformer language models have been directly fine-tuned, entirely removing the need for task-specific architectures.
However, a major limitation to this approach is that while the architecture is task-agnostic, there is still a need for task-specific datasets and task-specific fine-tuning.
Removing this limitation would be desirable, for several reasons.
First, from a practical perspective, the need for a large dataset of labeled examples for every new task limits the applicability of language models.
For many of these tasks it is difficult to collect a large supervised training dataset.
Second, the potential to exploit spurious correlations in training data fundamentally grows with the expressiveness of the model and the narrowness of the training distribution. This can create problems for the pre-training plus fine-tuning paradigm, where models are designed to be large to absorb information during pre-training, but are then fine-tuning on very narrow task distributions.
For instance observe that larger models do not necessarily generalize better out-of-distribution. There is evidence that suggests that the generalization achieved under this paradigm can be poor because the model is overly specific to the training distribution and does not generalize well outside it.
Third, humans do not require large supervised datasets to learn most language tasks - a brief directive in natural language or at most a tiny number of demonstrations is often sufficient to enable to human perform a new task to at least a reasonable degree of competence.
한계점 해결 방법에는 meta-learning이 있다. 언어 모델 측면에서 meta-learning이란, 모델이 학습 시간에 수많은 스킬 및 패턴 인지 능력을 학습하여, 추론 시간에 이러한 능력으로 task에 빠르게 적응 및 인식하는 방법을 말한다. 최근 연구에서 in-context learning으로 meta-learning을 진행하려는 시도가 있었다. in-context learning이란 텍스트로 구성된 task 설명 및 시연을 입력값으로 주고, 이를 기반으로 pre-trained 언어 모델이 다음 token을 추론하는 방식으로 마지막 문제의 정답을 완성하는 방식이다.
하지만, 위 접근법은 아직까지 fine-tuning 기법에 비해 성능이 매우 안 좋다. 때문에, 실용적인 방법이 되기 위해서는 meta-learning의 상당한 개선이 필요하다.
One potential route towards addressing these issues is meta-learning - which in the context of language models means the model develops a broad set of skills and pattern recognition abilities at training time, and then uses those abilities at inference time to rapidly adapt to or recognize the desired task. Recent work attempts to do this via what we call "in-context learning", using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
this approach still achieves results far inferior to fine-tuning.
Meta-learning clearly requires substantial improvement in order to be viable as a practical method of solving language tasks.
최근 몇 년 동안, transformer 언어 모델의 역량(=capacity)이 매우 커졌다. "수많은 task 성능과 상관관계가 있는 log loss가 모델 크기와 비례하다"는 결과가 그 증거다. 수많은 스킬 및 task를 paramater에 저장하는 것이 in-context learning의 핵심이기에, 위 결과는 "in-context learning이 모델 크기에 비례해 큰 힘을 발휘할 수 있다"라는 가정을 할 수 있다.
이번 연구에서는, 위 가정을 증명하기 위해 1750억 파라미터 자기 회귀 언어 모델 즉, GPT-3를 학습시킨 후, in-context learning 성능을 측정해 볼 것이다.
3가지 관점에서 GPT-3의 task 성능을 평가할 것이다. 1. few-shot learning (or in-context learning): 최대한 많은 시연을 포함한다. 2. one-shot learning: 한 개의 시연을 포함한다. 3. zero-shot learning: 시연을 포함하지 않고 오직 task 설명만 포함한다.
few-shot은 모델에게 task와 관련 없는 단어를 배제할 수 있도록 도와준다.
모델 성능은 task 설명이 추가되거나, 시연 개수가 많아질수록 높아진다. 뿐만 아니라 few-shot learning은 모델 크기에 따라 성능이 극적으로 향상된다.
one-shot과 few-shot 간의 진보 즉, 사연 개수 차이가 얼마큼 성능 차이를 내는지 관찰하기 위해, 빠른 적응 task와 즉각적인 추론 task를 수행할 것이다.
동시에, 모델 크기 확장을 최대로 한 GPT-3도 고전한 몇 가지 task(=자연어 추론 task 및 독해 이해 task)를 살펴볼 것이다.
이번 연구에서는, 데이터 감염 (or 오염) 문제에 관한 체계적인 연구도 진행할 것이다. Common Crawl와 같은 dataset으로 역량 높은 모델을 학습시킬 때, 데이터 감염 문제는 더욱 커진다. Common Crawl에 테스트 데이터가 포함됐기 때문이다.
이번 연구에서는, 데이터 감염 정도를 측정하고 성능 왜곡 영향을 수치화할 것이다. 다행히도, 데이터 감염에 따른 GPT-3의 성능 왜곡은 미미하다.
이번 연구에서 주목할 만한 패턴은 "모델 역량이 커질수록 zero-, one-, few-shot의 성능의 차이가 커진다"는 것이다. 다시 말해, 가장 큰 모델이 in-context learning의 최대 수혜자다.
In recent years, the capacity of transformer language models has increased substantially.
there is evidence suggesting that log loss, which correlates well with many downstream tasks, follows a smooth trend of improvement with scale. Since in-context learning involves absorbing many skills and tasks within the parameters of the model, it is plausible that in-context learning abilities might show similarly strong gains with scale.
In this paper, we test this hypothesis by training a 175 billion parameter autoregressive language model, which we call GPT-3, and measuring its in-context learning abilities.
For each task, we evaluate GPT-3 under 3 conditions: (a) "few-shot learning", or in-context learning where we allow as many demonstrations as will fit into the model's context window, (b) "one-shot learning", where we allow only one demonstration, and (c) "zero-shot learning", where no demonstrations are allowed and only instruction in natural language is given to the model.
few-shot learning of a simple task requiring the model to remove extraneous symbol from a word.
Model performance improves with the addition of a natural language task description, and with the number of examples in the model's context. Few-shot learning also improves dramatically with model size.
GPT-3 also displays one-shot and few-shot proficiency at tasks designed to test rapid adaption or on-the-fly reasoning.
At the same time, we also find some tasks on which few-shot performance struggles, even at the scale of GPT-3. This includes natural language inference tasks like the ANLI dataset, and some reading comprehension datasets like RACE.
We also undertake a systematic study of "data contamination" - a growing problem when training high capacity models on datasets such as Common Crawl, which can potentially include content from test datasets simply because such content often exists on the web. In this paper, we develop systematic tools to measure data contamination and quantify its distorting effects.
data contamination has a minimal effect on GPT-3's performance on most datasets.
one notable pattern is that the gap between zero-, one-, few-shot performance often grows with model capacity, perhaps suggesting that larger models are more proficient meta-learners.
2. Approach
모델, 데이터, 학습을 포함한 pre-training 방식은 GPT-2랑 매우 유사하다. GPT-2에 비해 모델 크기가 커졌고, dataset 크기와 다양성이 확장됐다. 뿐만 아니라 학습 시간도 늘어났다.
in-context learning 또한 GPT-2 논문과 비슷하다. 하지만, 이번 연구에서는 3가지 관점을 체계적으로 분석 및 비교해볼 것이다.
1. Fine-Tuning은 pre-trained 모델 가중치를 task에 맞게 변경하는 방식으로, 최근에 가장 많이 사용하는 방식이다.
위 방식은 task에서 강력한 성능을 발휘한다. 하지만, task 학습을 위해 수 만개의 dataset이 필요하고 OOD 일반화가 어렵다. 뿐만 아니라, 학습 dataset의 허위 관계를 학습할 가능성이 높다.
2. Few-Shot은 추론 시간에 모델에게 여러 개의 시연을 입력값으로 제공한다. 모델은 그것을 기반으로 task가 무엇인지 인지하여 추론을 진행한다. 이때 모델의 가중치 변화는 없다.
자세히 말하자면, 지문(=context)과 답(=completion)을 갖고 있는 K개의 문제(=시연)와 마지막 문제의 지문을 입력값으로 제공한다. 그 후, 모델은 이를 기반으로 마지막 문제의 답을 추론한다.
위 방식은 task 학습에 필요한 dataset 개수를 획기적으로 줄여준다. 뿐만 아니라, dataset의 허위 관계를 학습할 가능성이 낮다. (매우 소량의 dataset을 parameter 수정에 사용하지 않고, 입력값으로 주어졌기 때문이다?, 아니면, pre-training dataset에 관련된건가?) 하지만, state-of-the-art 모델과 성능 차이가 있다.
3. One-Shot은 한 개의 시연만 제공한다는 점 외에는 few-shot과 동일하다.
4. Zero-Shot은 시연을 제공하지 않는다는 점 외에는 one-shot과 동일하다. 다시 말해, 모델에게 task 설명만 제공된다. 위 방식은 제약이 거의 없어 매우 편하고, dataset의 허위 관계를 고려하지 않아도 된다. 하지만, 가장 도전적인 방식이다.
이번 연구를 통해, GPT-3의 few-shot 성능이 state-of-the-art 모델 성능에 매우 근접하다는 것을 강조하고 싶다.
Our basic pre-training approach, including model, data, and training, is similar to the process described in GPT-2 paper with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training. Our use of in-context learning is also similar with GPT-2 paper, but in this work we systematically explore different settings for learning within the context.
Fine-Tuning (FT) has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task.
The main advantage of fine-tuning is strong performance on many benckmarks. The main disadvantages are the need for a new large dataset for every task, the potential for poor generalization out-of-distribution, and the potential to exploit spurious features of the training data, potentially resulting in an unfair comparison with human performance.
Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed.
few-shot works by giving K examples of context and completion, and then final example of context, with the model expected to provide the completion.
The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution.
The main disadvantages is that results from this method have so far been much worse than state-of-the-art fine-tuned models.
One-Shot (1S) is the same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task.
Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. maximum convenience, potential for robustness, and avoidance of spurious correlations, but is also the most challenging setting.
We especially highlight the few-shot results as many of them are only slightly behind state-of-the-art fine-tuned models.
2.1. Model and Architecture
GPT-3의 모델 구조는 GPT-2와 동일하다.
이번 연구에서는 여러 크기의 모델을 학습하여, "충분한 dataset이 있으면, 모델 크기에 비례해 validation loss가 줄어든다"라는 가정을 증명할 것이다.
we use the same model and architecture as GPT-2, including the modified initialization, pre-normalization, and reversible(=invertible=1-to-1) tokenization described therein, with exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar with Sparse Transformer.
Previous work suggests that with enough training data, scaling of validation loss should be approximately a smooth power law as a function of size; training models of many different sizes allow us to test this hypothesis both for validation loss and for downstream language tasks.
2.2. Training Dataset
최근 언어 모델에 대한 dataset이 빠르게 확장되고 있다. 대표적으로 1조 개의 단어로 구성된 Common Crawl이 있다. 하지만, 필터링되지 않거나 가볍게 필터링된 Common Crawl 버전은 품질이 매우 떨어지는 것을 발견했다. 품질을 높이기 위해 세 단계 전처리를 진행할 것이다. 첫 번째, 필터링된 Common Crawl 버전 중 고품질 말뭉치와 유사성이 먼 것만 사용한다. 두 번째, 데이터 중복을 없애고 검증 데이터의 무결성을 유지하기 위해, dataset 간의 문서 수준의 중복 제거를 실행한다. 마지막으로, 고품질 말뭉치를 학습 데이터에 추가해 다양성을 높힐 것이다.
학습 시, dataset은 크기에 비례하지 않고, dataset의 품질에 비례한다.
이는 고품질 dataset을 자주 학습하는 이점이 있지만, 모델이 고품질 dataset에 과적합된다는 단점이 있다.
광범위한 인터넷 dataset으로 언어 모델을 학습할 경우 특히, 다량의 글을 기억할 수 있는 언어 모델을 학습시킬 때 주의할 점은 task의 감염이다. 다시 말해, 테스트 데이터 혹은 검증 데이터가 학습 데이터에 존재해, 답지를 미리 본 경우를 말한다. 이러한 감염을 방지하기 위해 이번 연구에서는, 학습 데이터에서 테스트 데이터와 검증 데이터 겹치는 부분을 제거할 것이다.
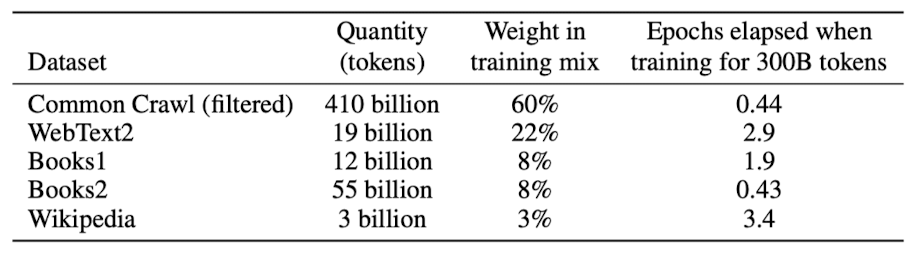
Datasets for language models have rapidly expanded, culminating in the Common Crawl dataset constituting nearly a trillion words.
However, we have found that unfiltered or lightly filtered versions of Common Crawl tend to have lower quality than more curated datasets. Therefore, we took 3 steps to improve the average quality of our datasets: (1) we downloaded and filtered a version of CommonCrawl based on similarity to a range of high-quality reference corpora, (2) we performed fuzzy deduplication at the document level, within an across datasets, to prevent redundancy and preserve the integrity of our held-out validation set as an accurate measure of overfitting, and (3) we also added known high-quality reference corpora to the training mix to augment CommonCrawl and increase its diversity.
Details of the first two points are described in Appendix A.
Note that during training, datasets are not sampled in proportion to their size, but rather datasets we view as higher-quality are sampled more frequently.
This essentially accepts a small amount of overfitting in exchange for higher quality training data.
A major methodological concern with language models pretrained on a broad swath of internet data, particularly large models with the capacity to memorize vast amounts of content, is potential contamination of downstream tasks by having their test or development sets inadvertently seen during pre-training. To reduce such contamination, we searched for and attempted to remove any overlaps with the development and test sets of all benchmarks studied in this paper.
2.3. Training Process
이전 연구에서 발견된 거와 같이, 더 큰 모델은 더 큰 배치 크기를 사용할 수 있지만, 이는 더 작은 학습률을 요구한다. 때문에, 학습 도중에 측정한 기울기 노이즈 정도를 기반으로 배치 크기를 선정한다.
메모리 부족 없이 큰 모델을 학습시키기 위해, 모델 병렬 기법(=pipeline-parallelism, tensor-parallelism)을 사용한다.
As found in studies, larger models can typically use a larger batch size, but require a smaller learning rate. We measure the gradient noise scale during training and use it to guide our choice of batch size.
To train the larger models without running out of memory, we use a mixture of model parallelism with each matrix multiply and model parallelism across the layers of the network.
2.4. Evaluation
Fow-shot을 평가할 때, task의 학습 데이터에서 K개의 시연을 무작위로 가져온 후, 시연을 한 줄 혹은 두 줄로 구분해 입력값으로 제공한다.
K개가 커질수록 성능이 무조건 좋아지는 것은 아니다. 그렇기 때문에, 검증 데이터와 테스트 데이터가 분리되어 있는 경우, 검증 데이터로 최적의 K를 선정한다. 이때, 특정 task에는 task 설명을 입력값에 추가한다.
객관식 형태의 task에서는, 지문과 정답을 포함한 K개의 문제(=시연)와, 풀어야 할 문제의 지문이 주어진다. 이때 모델은 이를 기반으로 모든 선지의 확률을 계산한다.
이진 분류 형태의 task에서는, 문제 형태를 객관식 형태로 수정한다. (e.g., 1. True, 2. False)
주관식 형태의 task에서는, beam search를 통해 정답을 추론한다.
테스트 데이터가 공개된 task인 경우, 각 setting 방식 및 모델 크기에 대한 결과를 모두 발표할 것이다. 하지만, 테스트 데이터가 비공개인 경우, 검증 데이터의 결과로 발표할 것이다.
For few-shot learning, we evaluate example in the evaluation set by randomly drawing K examples from that task's training set as conditioning, delimited by 1 or 2 newlines depending on the task.
Larger values of K are usually but not always better, so when a separate development and test set are available, we experiment with a few values of K on the development set and then run the best value on the test set. For some tasks (see Appendix G) we also use a natural language prompt in addition to (or for K = 0, instead of) demonstrations.
On tasks that involve choosing one correct completion from several options (multiple choice), we provide K examples of context plus correct completion, followed by one example of context only, and compare the LM likelihood of each completion.
On tasks that involve binary classification, we give the options more semantically meaningful names and then treat the task like multiple choice;
On tasks with free-form completion, we use beam search with the same parameter as other study; a beam width of 4 and a length penalty of $\alpha$ = 0.6.
Final results are reported on the test set when publicly available, for each model size and learning setting (zero-, one- and few-shot). When test set is private, we report results on the development set. We do submit to the test server on a small number of datasets. and we submit only the 200B few-shot results.
3. Results
이전 연구에서 언어 모델링 성능과 학습에 사용된 계산량 간의 관계가 power-law임을 발견했다. 이번 연구에서는, 이 관계가 추가적인 $10^2$배에도 여전히 유지되고 있음(약간의 편차가 존재함)을 보여준다.
물론, "cross-entropy 손실 감소가 pre-training 말뭉치의 허위 관계 모델링에서 비롯될 수 있다"는 우려를 할 수 있다.
하지만, cross-entropy 손실 감소가 광범위한 자연어 task의 일관된 성능 향상으로 이어지기 때문에, 우려할 필요가 없어졌다.
As Observed in previous works, language modeling performance (measured in terms of cross-entropy validation loss) follows a power-law trend with the amount of compute used for training. The power-law behavior observed in previous paper continues for an additional two orders of magnitude with only small deviations from the predicted curve.
One might worry that these improvements in cross-entropy loss come only from modeling spurious details of our-training corpus. However, we will see in the following sections that improvements in cross-entropy loss lead to consistent performance gains across a broad spectrum of natural language tasks.
3.1. Language Modeling, Cloze, and Completion Tasks
이번 단락에서는, 언어 모델의 전통적인 task에 대해 살펴볼 것이다.
In this section we test GPT-3's performance on the traditional task of language modeling, as well as related tasks that involve predicting a single word of interest, completing a sentence or paragraph, or choosing between possible completion of a piece of text.
3.1.1. Language Modeling
pre-training dataset과 많이 겹치는 dataset(=4 Wikipedia, one-billion benchmark)은 빼고, 최근 인터넷 자료로 구성된 PTB만 사용했다. GPT-3의 zero-shot 성능이 20.50점이 나오면서 15점 차이로 SOTA(35.50점)를 갱신했다.
We calculate zero-shot perplexity on the Penn Tree Bank (PTB) dataset measured in GPT-2 paper. We omit the 4 Wikipedia-related tasks in that work because they are entirely contained in our training data, and we also omit the one-billion word benchmark due to a high fraction of the dataset being contained in our training set. PTB escapes these issues due to predating the modern internet. Our largest model sets a new SOTA on PTB by a substantial margin of 15 points, achieving a perplexity of 20.50.
3.1.2. LAMBADA
LAMBADA는 텍스트의 장기의존성을 평가하는 dataset이다. 즉, 문단을 기반으로 마지막 단어를 추론하는 task다.
최근에, 언어 모델의 확장이 이와 같은 task 성능에 큰 효과가 없다는 의견이 제기됐다.
하지만, 주장과 다르게 GPT-3의 zero-shot 성능이 이전 SOTA(68%)보다 8% 높은 76%를 보이면서, 언어 모델 확장이 성능에 큰 효과가 있음을 보였다.
더 나아가, LAMBADA에서 (모델에게 문제 해결 방향을 제공하는) few-shot의 이점을 확인할 수 있었다.
비록 LAMBADA의 추론 단어가 문단의 마지막 단어지만, 일반적인 언어 모델은 이를 알 방법이 없다. 그렇기 때문에, 문단을 마치는 단어뿐만 아니라 문단을 이어가는 단어에도 높은 확률을 부여한다. 하지만, few-shot은 모델에게 cloze-task로 인식시켜, 문단을 마치는 단어를 추론하게 만든다.
GPT-3의 few-shot 성능은 이전 SOTA(68%)보다 18% 높은 86%를 보였다. 그리고 모델 크기가 증가할수록 성능이 급격히 향상되는 것을 관찰했다.
one-shot은 zero-shot보다 성능이 떨어진다. 문제를 인식하기 위해서는 여러 개의 시연이 필요한 것이 이유일 수 있다.

The LAMBADA dataset tests the modeling of long-range dependencies in text - the model is asked to predict the last word of sentences which require reading a paragraph of context. It has recently been suggested that the continued scaling of language models is yielding diminishing returns on this difficult benchmark.
We find that path is still promising and in zero-shot setting GPT-3 achieves 76% on LAMBADA, a gain of 8% over the previous state of the art.
LAMBADA is also a demonstration of the flexibility of few-shot learning as it provides a way to address a problem that classically occurs with this dataset. Although the completion in LAMBADA is always the last word in sentence, a standard language model has no way to knowing this detail. It thus assigns probability not only to the correct ending but also to other valid continuations of the paragraph.
The few-shot setting instead allows us to "frame" the task as a cloze-task and allows the language model to infer from examples that a completion of exactly one word is desired.
When presented with examples formatted this way, GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art. We observe that few-shot performance improves strongly with model size.
Finally, the fill-in-blank method is not effective one-shot, where it always performs worse than the zero-shot setting. Perhaps, this is because all models still require several examples to recognize the pattern.
3.1.3. HellaSwag
HellaSwag은 이야기 혹은 지시 사항(e.g., 레시피)에 가장 적합한 결말을 선택하는 task다.
GPT-3의 one-shot일 때 78.1%, few-shot일 때 79.3% 성능을 보였지만, SOTA(85.6%)에는 도달하지 못했다.

The HellaSwag dataset involves picking the best ending to a story or set of instructions.
GPT-3 achieves 78.1% accuracy in the one-shot setting and 79.3% accuracy in the few-shot setting
still a fair amount lower than the overall SOTA of 85.6%
3.1.4. StoryCloze
StoryCloze2016은 다섯 문장으로 구성된 이야기의 결말 문장을 선택하는 task다.
GPT-3의 one-shot일 때 83.2%, few-shot일 때 87.7% 성능을 보였지만, 4.1%가 부족해 SOTA(91.8%)에 도달하지 못했다.

We next evaluate GPT-3 on the StoryCloze 2016 dataset, which involves selecting the correct ending sentence for five-sentence long stories. Here GPT-3 achieves 83.2% in the zero-shot setting and 87.7% in the few-shot setting (with K=70). This is still 4.1% lower than the fine-tuned SOTA
3.2. Closed Book Question Answering
이번 단락에서는, 광범위한 사실적 지식을 물어보는 task에 대한 GPT-3 성능에 대해 살펴볼 것이다.
관련 연구에서는, "큰 언어 모델이 추가적인 정보(=검색 시스템) 없이 정답을 더 잘 맞출 수 있다"라는 것을 보였다.
이는 역량이 더 높은 모델이 보다 높은 성능을 보일 수 있음을 암시하기 때문에, GPT-3를 통해 이 가정을 확인해 볼 것이다.
3가지 dataset(Natural Questions, WebQuestion, TriviaQA)으로 GPT-3의 성능을 평가해 볼 것이다.
1. TriviaQA: one-shot 성능이 open-domain의 SOTA(68%)와 동일한 성능을 보였고, few-shot(71.2%)은 3.2% 더 높은 성능을 보였다.

2. WebQs: few-shot 성능(41.5%)이 SOTA(45.5%)와 3% 차이로 거의 비슷한 수준을 보였다.
TriviaQA와 다르게, zero-shot(14.4%)에서 few-shot(41.5%)으로 변경하면 성능이 급격히 향상된다. 이는 WebOs가 GPT-3의 OOD일 수 있다는 것을 시사한다.

3. NQs: WebQs와 비슷하게, zero-shot(14.6%)에서 few-shot(29.9%)으로 변경하면 성능이 매우 급격히 향상된다. 때문에, NQs 또한 GPT-3의 OOD일지도 모른다. 이 때문인지 TriviaQA와 WebQs보단 성능이 낮게 나왔다.
NQs는 매우 세밀한 지식을 물어보는 경향이 있다. 이는 GPT-3의 역량과 분포의 범위의 한계를 평가하기에 적절한 dataset이다.

마지막으로 정리하자면, 3가지 dataset 모두 모델 크기에 비례해 성능이 향상되는 걸 볼 수 있다. 이는 "모델 역량이 뛰어나다"는 것이 "더 많은 "지식"을 parameter가 가지고 있다"라는 것으로 해석할 수 있음을 시사한다.
In this section we measure GPT-3's ability to answer questions about broad factual knowledge.
related study recently demonstrated that a large language model can perform surprisingly well directly answering the questions without conditioning on auxiliary information.
Their work suggests that even higher-capacity models could perform even better and we test this hypothesis with GPT-3. We evaluate GPT-3 on the 3 datasets, Natural Questions, WebQuestions, and TrivialQA, using the same splits.
On TriviaQA, the one-shot matches the SOTA for an open-domain QA system.
GPT-3's few-shot result further improves performance another 3.2% beyond this.
On WebQuestions (WebQs), GPT-3 in the few-shot setting approaches the performance of state-of-the-art fine-tuned models. Notably, compared to TrivialQA, WebQs shows much larger gain from zero-shot to few-shot, perhaps suggesting that the WebQs questions and/or the style of their answers are out-of-distribution for GPT-3.
On Natural Questions (NQs), similar to WebOs, the large gain from zero-shot to few-shot may suggest a distribution shift(=training and test sets do not come from the sam distribution).
In particular, the questions in NQs tend towards very fine-grained knowledge on Wikipedia specifically which could be testing the limits of GPT-3's capacity and broad pretraining distribution.
Overall, on one of the three datasets GPT-3's one-shot matches the open-domain fine-tuning SOTA. On the other two datasets it approaches the performance of the closed-book SOTA
On all 3 datasets, we find that performance. scales very smoothly with model size, possibly reflecting the idea that model capacity translates directly to more "knowledge" absorbed in the parameters of the model.
3.3. Translation
이번 연구에서는, GPT-2보다 역량이 100배 더 큰 GPT-3를 만들었기 때문에, 영어 외의 언어들을 pre-training dataset에 포함시켜 범위를 확장했다.
GPT-3의 zero-shot 성능은 이전 NMT(=Neural Machine Translation)에 비해 매우 떨어지지만, one-shot 성능은 어느 정도 견줄 수 있는 정도다. 더 나아가, few-shot 성능은 NMT와 유사한 수준을 보였다.
GPT-3의 few-shot은 다음과 같은 특징을 보였다. 영어로 번역할 때, 이전 NMT보다 높은 성능을 보인 반면, 다른 언어로 번역할 때는 이전 NMT보다 낮은 성능을 보였다. 영어 tokenizer를 사용한 것이 원인이 될 수 있다.
마지막으로, 3가지 관점(zero-, one-, few-shot) 뿐만 아니라 언어별 번역 모두 모델 크기에 비례해 성능이 향상된다.

Since we increase the capacity by over two orders of magnitude from GPT-2 to GPT-3, we also expand the scope of the training dataset to include more representation of other languages. Zero-shot GPT-3 still underperforms recent unsupervised NMT(Neural Machine Translation) results. However, providing only a single example demonstration for each translation task improves performance by over 7 BLUE and nears competitive performance with prior work. GPT-3 in the full few-shot setting improves further another 4 BLEU resulting in similar average performance to prior unsupervised NMT work.
GPT-3 significantly outperforms prior unsupervised NMT work when translating into English but underperforms when translating in the other direction.This could be a weakness due to reusing the byte-level BPE tokenizer of GPT-2 which was developed for an almost entirely English training dataset. Finally, across all language pairs and across all three settings (zero-, one-, few-shot), there is a smooth trend of improvement with model capacity.
3.4. Winograd-Style Tasks
이번 단락에서는, 문법적으로 모호하지만 문맥상 모호하지 않은 대명사가 어떤 명사를 지칭하는지 찾는 task에 대해 살펴볼 것이다. 대표적으로 Winograd dataset이 있다.
참고로, context를 기반으로 target completion을 예측하는 조건부 확률 즉, "partial evalution"으로 GPT-3를 평가할 것이다.
GPT-3의 zero-, one-, few-shot에서 88.3%, 89.7%, 88.6%를 보였다. 이는 SOTA(90.1%)와 거의 비슷한 성능이지만, in-context learning 이점은 찾아볼 수 없었다.
보다 더 어려운 Winogrande dataset에서는 zero-, one-, few-shot 각각 70.2%, 73.2%, 77.7%를 보이면서, in-context learning 이점을 볼 수 있었다. 하지만, SOTA(84.6%)와 성능 차이가 났다.

The Winograd Schemas Challenge is a classical task in NLP that involves determining which word a pronoun refers to, when the pronoun is grammatically ambiguous but semantically unambiguous to a human.
On Winograd we test GPT-3 on the original test of 273 Winograd schemas, using the same "partial evaluation" method described in GPT-2 paper.
On Wingorad GPT-3 achieves 88.3%, 89.7%, and 88.6% in the zero-shot, one-shot, and few-shot settings, showing no clear in-context learning but in all cases achieving strong results just a few points below state-of-the-art and estimated human performance.
On the more difficult Winogrande dataset, we do find gains to in-context learning; GPT-3 achieves 70.2% in the zero-shot setting, 73.2% in the one-shot setting, and 77.7% in the few-shot setting.
state-of-the-art is 84.6% achieved with a fine-tuned high capacity model (T5).
3.5. Common Sense Resoning
이번 단락에서는, 물리 혹은 과학적 지식을 물어보는 task에 대해 살펴볼 것이다. 사용할 dataset으로는 3가지로 PIQA, ARC, OpenBookQA가 있다.
1. PIQA는 물리적으로 현실 세계가 어떻게 움직이는지에 대한 상식적인 질문을 수집한 dataset이다.
PIQA는 모델 크기에 비례해 성능이 향상된다. GPT-3의 few-shot 성능(82.8%)은 사람의 성능(92.8%)보다 10% 낮지만, SOTA(79.4%)를 능가했다. 참고로, zero-shot(81.0%)도 SOTA를 능가했다!! 하지만 불행하게도, 분석을 통해 데이터 오염 문제가 발견됐다.

2. ARC는 객관식으로 3학년부터 9학년까지 과학시험문제를 수집한 dataset이다. 심화 문제들에서는, 53.2%, 53.2%, 51.5%를 보였고, 기본 문제에서는, 68.7%, 71.2%, 70.1%를 보였다. 이 둘 다 SOTA(78.5%)와 큰 성능 차이를 보였다.

3. OpenBookQA에서는, zero-shot(57.6%)에서 few-shot(65.4%)으로 변경하면 성능이 향상된다. 하지만, SOTA(87.2%)와 20% 차이가 났다.
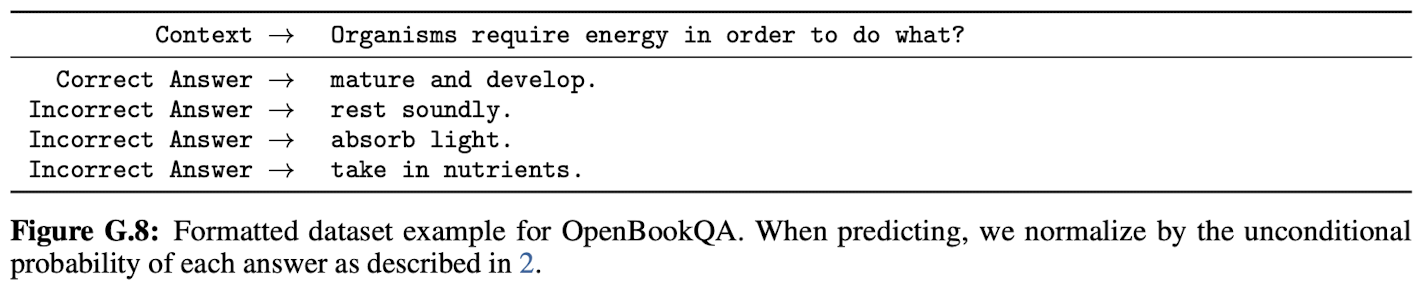
마지막으로, 과학 지식 추론 task에서는 in-context learning 이점이 불분명하다. 즉, 있을 때(OpenBookQA)도 있고 없을 때(PIQA, ARC)도 있다.
Next we consider three datasets which attempt to capture physical or scientific reasoning , as distinct from sentence completion, reading comprehension, or broad knowledge question answering. The first, PhysicalQA (PIQA) asks common sense questions about how the physical world works and is intended as a probe of grounded understanding of the world.
PIQA shows relatively shallow scaling with model size and is still over 10% worse than human performance, but GPT-3's few-shot and even zero-shot result outperform the current state-of-the-art. Our analysis flagged PIQA for a potential data contamination issue, and we therefore conservatively mark the result with an asterisk.
ARC is a dataset of multiple-choice questions collected from 3rd to 9th grade science exams. On the "Challenge" version of the dataset, GPT-3 achieves 51.4% accuracy in zero-shot setting, 53.2% in the one-shot setting, and 51.5% in the few-shot setting. On the "Easy" version of the dataset, GPT-3 achieves 68.7%, 71.2% and 70.1%.
However, both of these results are still much worse than the overall SOTAs.
On OpenBookQA, GPT-3 improves significantly from zero to few shot settings but is still over 20 points short of the overall SOTA.
Overall, in-context learning with GPT-3 shows mixed results on commonsense reasoning tasks, with only small and inconsistent gains observed in the one and few-shot learning settings for both PIQA and ARC, but a significantly improvements is observed on OpenBookQA.
3.6. Reading Comprehension
이번 단락에서는, 독해에 관련된 task에 대해 살펴볼 것이다. 대표적으로 지문 내용 추상화, 지문 내용에 관련된 객관식 혹은 주관식 문제가 있다.
사용할 dataset으로는 5가지로 CoQA, QuAC, DROP, SQuAD 2.0, RACE가 있다.
일반적으로, GPT-3 성능은 기본 baseline과 비슷하다.





We use suite of 5 datasets including abstractive, multiple choice, and span based answer formats in both dialog and single question settings.
In general we observe GPT-3 is on par with initial baselines and early results trained using contextual representation on each respective dataset.
3.7. SuperGLUE
NLP tasks 성능을 정확히 집계하고, 유명 모델과 성능 비교를 체계적으로 하기 위해선, SuperGLUE benchmark와 같은 표준 dataset 모음으로 GPT-3를 평가해야 한다.
여기서 주목해야할 부분은 바로 WiC의 few-shot이다. 성능이 49.9%가 나오면서 GPT-3의 few-shot 약점으로 대두됐다. 이 현상은 다음 단락을 통해 더욱 명확해질 것이다.
자세히 말하자면, GPT-3의 one-shot과 few-shot 모두 "두 문장을 비교하는 task"에서 약점을 보인다. 대표적으로, 단어가 두 문장에 같은 의미로 사용되었는지(=WiC), 한 문장이 다른 문장을 의역한 건지(=CB), 한 문장이 다른 문장 의미를 내포하고 있는지(=RTE)를 판단하는 task가 있다. 이는 CB와 RTE가 왜 낮은 성능 보이는지 설명해 준다.
이러한 약점에도 불구하고, GPT-3는 8가지 task 중 4가지에서 fine-tuned BERT-large보다 높은 성능을 보였다. 마지막으로, SuperGLUE의 few-shot 성능은 모델 크기와 시연 개수에 비례해 성능이 향상된다. 이는 in-context learning 이점이 존재함을 방증하는 현상이다.



In order to better aggregate results on NLP tasks and compare to popular models such as BERT and RoBERTa in a more systematic way, we also evaluate GPT-3 on a standardized collection of datasets, the SuperGLUE benchmark.
WiC is notable weak spot with few-shot performance at 49.4% (at random chance). This hints at a phenomenon that will become clearer in the next section (which discusses the ANLI benckmark) - GPT-3 appears to be weak in the few-shot or one-shot setting at some tasks that involve comparing two sentences or snippets, for example whether a word is used the same way in two sentences (WiC), whether one sentence is a paraphrase of another, or whether one sentence implies another. This could explain the comparatively lower scores of RTE and CB. Despite these weakness, GPT-3 still outperforms a fine-tuned BERT-large on four of eight tasks and on two tasks GPT-3 is close to the state-of-the-art. Finally, we note that the few-shot SuperGLUE score steadily improves with both model size and with number of examples in the context showing increasing benefits from in-context learning.
3.8. NLI
자연어 추론이란 두 문장 간의 관계를 이해하는 능력과 관련된 task다. 일반적으로, 첫 문장이 다음 문장과 자연스러운지, 모순되는지, 그럴싸한지 판별하도록 task를 설계한다. SuperGLUE는 RTE와 같은 NLI dataset을 포함하고 있다.
이번에는 ANLI로 평가할 것이다. ANLI는 적대적으로 수집한 자연어 추론 문제를 보유하고 있는 dataset이다. ANLI에는 난이도에 따라 문제를 세 가지(R1, R2, R3)로 분류할 수 있다. RTE와 비슷하게, GPT-3를 제외한 나머지 모델의 one-shot과 few-shot 성능은 무작위 추론과 비슷한 성능(33%)을 보였다. 이러한 결과들은 언어 모델이 NLI에 취약하는 것을 시사한다.

Natural Language Inference (NLI) concerns the ability to understand the relationship between two sentences. In practice, this task is usually structured as a two or three class classification problem where the model classifies whether the second sentence logically follows from the first, contradicts the first sentence, or possibly true (neutral). SuperGLUE includes an NLI dataset, RTE, which evaluates the binary version of the task.
We also evaluate on the recently introduced Adversarial Natural Language Inference (ANLI) dataset. ANLI is a difficult dataset employing a series of adversarially mined natural language inference questions in three rounds (R1, R2, and R3). Similar to RTE, all of our models smaller than GPT-3 perform at almost exactly random chance on ANLI, even in the few-shot setting(~33%).
These results on both RTE and ANLI suggest that NLI is still a very difficult task for language models and they are only just beginning to show signs of process.
3.9. Synthetic and Qualitative Tasks
GPT-3의 few-shot learning 역량을 파악하기 위한 방법으로는 (pre-training dataset에서는 보지 못한) 새로운 패턴 인지 (or 적응)을 요하는 task로 모델을 평가하는 것이다.
One way to probe GPT-3's range of abilities in the few-shot (or zero- and one-shot) setting is to give it tasks which require it to perform simple on-the-fly computational reasoning, recognize a novel pattern that is unlikely to have occur in training, or adapt quickly to an unusual task.
3.9.1. Arithmetic
이번에는 간단한 사칙연산 task에 대해 살펴볼 것이다.
GPT-3의 few-shot 성능은 다음과 같다. 1). 자릿수가 작을 때, 합과 차의 성능은 높다. 하지만, 자릿수가 커짐에 따라 성능이 감소한다. 2). 두 자릿수 곱에서는 29.2% 성능을, 두 번 연산에서는 21.3% 성능을 보였다.
one-shot과 zero-shot의 성능이 few-shot에 비해 상대적으로 낮다. 이는 task의 빠른 적응이 성능에 큰 영향을 끼친다는 것을 시사한다.
2000개의 합 문제 중 17개가 pre-training dataset에 발견됐고, 2000개의 차 문제 중 2개가 pre-training dataset에 발견됐다.
이는 무시할 정도의 수준이다. 즉, 모델의 답 암기로 성능을 향상시킨 정도가 미미하다는 것이다. 게다가, 1을 포함하지 않아 오답으로 된 것들을 보면, 모델이 답을 암기해 문제를 푼다고 할 수 없다.
마지막으로 정리하자면, zero-, one-, few-shot 모두 산술 task에서 적당한 성능을 보여줬다.

To test GPT-3's ability to perform simple arithmetic operation without task-specific training, we developed a small battery of 10 tests that involve asking GPT-3 a simple arithmetic problem in natural language.
First we evaluate GPT-3 in the few-shot setting.
On addition and subtraction, GPT-3 displays strong proficiency when the number of digits is small.
Performance decreases as the number of digits increases.
GPT-3 also achieves 29.2% accuracy at 2 digit multiplication.
Finally, GPT-3 achieves 21.3% accuracy at single digit combined operations, suggesting that it has some robustness beyond just single operations.
small models do poorly on all of these tasks
One-shot and zero-shot performance somewhat degraded relative to few-shot performance, suggesting that adaptation to the task is important to performing these computations correctly.
Out of 2000 addition problems we found only 17 matches (0.8%) and out of 2000 subtraction problems we found only 2 matches (0.1%), suggesting that only a trivial fraction of the correct answers could have been memorized. In addition, inspection of incorrect answers reveals that the model often makes mistakes such as not carrying a "1", suggesting it is actually attempting to perform the relevant computation rather than memorizing a table.
Overall, GPT-3 displays reasonable proficiency at moderately complex arithmetic in few-shot, one-shot, and even zero-shot settings.
3.9.2. Word Scrambling and Manipulation Tasks
이번에는 단어 조작 task(단어를 뒤섞거나, 새로운 문자를 추가하거나, 기존 문자를 삭제하는 등의 단어 조작을 한 후, 원래 단어 복구를 요구하는 task)에 대해 살펴볼 것이다.
성능은 모델 크기에 비례해 향상된다. GPT-3의 few-shot에서는 무작위 문자 추가가 66.9%, 문자 순환이 38.6%, 문자 섞기(쉬운 버전)가 40.2%, 문자 섞기(심화 버전)가 15.1% 성능을 보였다. 불행하게도, 어느 모델도 역방향 조작은 복구하지 못했다.
one-shot에서는 성능이 더 안 좋아졌고, zero-shot에서는 대부분 단어를 복구하지 못했다. 이는 추론 시간에 task를 배웠다는 것을 의미한다.
모델이 더 클수록 in-context 정보 즉, 시연 개수와 task 설명을 더 잘 활용한다. 이 또한 in-context learning 이점이 존재함을 방증하는 현상이다.
마지막으로, 단어 조작 task를 풀기 위해선 문자 단위의 조작해야 한다. 하지만 GPT-2 BPE tokenizer는 단어 단위(~한 토큰 당 0.7개 단어)로 조작된다. 뿐만 아니라, 조작된 문자열로 만들 수 있는 단어가 한 개가 아니라 여러 개다. 이러한 특징들 때문에, 단어 조작 task를 풀기 위해선, 수준 높은 스킬과 패턴 인지 능력이 필요한 것으로 추정된다.


To Test GPT-3's ability to learn novel symbolic manipulations from a few examples, we designed a small battery of 5 "character manipulation" tasks. Each task involves giving the model a word distorted by some combination of scrambling, addition, or deletion of characters, and asking it to recover the original word.
Task performance tends to grow smoothly with model size, with the full GPT-3 model achieving 66.9% on removing random insertions, 38.6% in cycling letters, 40.2% on the easier anagram tasks, and 15.1% on the more difficult anagram task. None of the models can reverse the letters in a word.
In the one-shot setting, performance is significantly weaker, and in the zero-shot setting the model can rarely perform any of the tasks. This suggests that the model really does appear to learn these tasks at test time.
We can see that larger models are able to make increasingly effective use of in-context information, including both task examples and natural language task descriptions.
Finally, it is worth adding that solving these tasks requires character-level manipulations, whereas our BPE encoding operates on significant fractions of a word (on average ~ 0.7 words per token), so from the LM's perspective succeeding at these tasks involves not just manipulating BPE tokens but understanding and pulling apart their substructure. Also CL, A1 and A2 are not bijective requiring the model to perform some search to find the correct unscrambling. Thus, the skills involved appear to require non-trivial pattern-matching and computation.
3.9.3. SAT Analogies
SAT analogy는 2005년 이전 SAT의 한 부분 차지했던 객관식 문제로 특이한 텍스트 분포(pre-training dataset에서는 없는 분포)를 가지고 있으며, 다섯 개 단어 쌍 중에서 기존 단어 쌍과 가장 비슷한 관계를 갖는 단어 쌍을 찾는 문제다.
GPT-3의 zero-, one-, few-shot에서 65.2%, 59.1%, 53.7% 성능을 보였다. 대학 지원자들의 시험 평균은 57%다.
뿐만 아니라, 모델 크기에 비례해 성능이 향상된다.

To test GPT-3 on another task that is somewhat unusual relative to the typical distribution of text, we collected a set of 374 "SAT analogy" problems. Analogies are a style of multiple choice question that constituted a section of the SAT college entrance exam before 2005.
The student is expected to choose which of the five word pairs has the same relationship as the original word pair.
On this task GPT-3 achieves 65.2% in the few-shot setting, 59.1% in the one-shot setting, and 53.7% in the zero-shot setting, whereas the average score among college applicants was 57%
the results improve with scale.
3.9.4. News Article Generation
GPT-2에 비해, GPT-3는 뉴스 기사 dataset 비율이 높지 않다. 그렇기 때문에, 아무런 조건 없이 기사를 작성하는 것은 효과적이지 않다.
이를 해결하기 위해, 세 개의 뉴스 기사를 제공하는 방식으로 few-shot learning의 이점을 활용할 것이다.
실제 기사와 GPT-3가 작성한 기사를 사람이 직접 구분하는 방식으로 뉴스 기사 품질을 측정할 것이다.
80명의 미국인에게 실제 기사 혹은 GPT-3 작성한 기사를 제공해 구분하도록 요구한다.
참여자가 노력을 기울여 구분하는지 확인하기 위해, 다른 모델이 작성한 품질이 낮은 기사도 구분하도록 요구할 것이다.
품질 낮은 기사의 정답률이 86%가 되는 반면, GPT-3가 작성한 기사의 정답률은 50%에 육박한다.
뿐만 아니라, 정답률은 모델 크기에 반비례한다.
부정확한 사실은 분류 단서가 될 수 있다. 이러한 부정확한 사실은 기사 제목이 무엇을 의미하는지 혹은 기사가 언제 작성됐는지 등의 구체적인 사실을 모델이 모르기에 나올 수 있다. 또 다른 단서로는 반복, 비논리, 특이한 문구가 있다.
더 많은 단어를 읽을수록 정답률이 증가하는 것을 발견했다.
품질 낮고 긴 기사의 정답률은 ~88%고, GPT-3가 작성한 긴 기사는 52%다. 이는 실제 기사와 GPT-3가 작성한 기사를 구분하기 매우 어렵다는 것을 의미하며, 그만큼 품질이 좋다는 것을 의미한다.

Relative to GPT-2, the dataset used to train GPT-3 is much less weighted towards news articles, so trying to generate news articles via raw unconditional samples is less effective. To solve this problem we employed GPT-3's few-shot learning abilities by providing three previous news articles in the model's context to condition it.
To gauge the quality of news article generation from GPT-3, we decided to measure human ability to distinguish GPT-3 generated articles from real ones.
For each model, we presented around 80 US-based participants with a quiz consisting of these real titles and subtitles followed by either the human written article or the article generated by the model.
we also run an experiment to control for participant effort and attention that followed the same format but involved intentionally bad model generated articles.
Mean human accuracy at detecting that the intentionally bad articles were model generated was ~86%
By contrast, mean human accuracy at detecting articles that were produced by the 175B parameter model was barely above chance.
Human abilities to detect model generated text appear to decrease as model size increases.
Factual inaccuracies can be an indicator that an article is model generated since, unlike human authors, the models have no access to the specific facts that the article titles refer to or when the article was written. Other indicators include repetition, non sequiturs, and unusual phrasing.
human accuracy at detecting model generated text increases as human observe more tokens.
We found that mean human accuracy at detecting the intentionally bad longer articles from the control model was ~88%, while mean human accuracy at detecting the longer articles that were produced by GPT-3 175B was still barely above chance at ~52%. This indicates that, for new articles that are ground 500 words long, GPT-3 continues to produce article that humans find difficult to distinguish from human written news articles.
3.9.5. Learning and Using Novel Words
이번에는 새로운 단어를 사용하는 task(단어의 정의를 본 후, 단어를 사용해 새로운 문장을 생성하는 task, 혹은 반대로, 문장에 사용되는 것을 보고 단어의 정의를 추론하는 task)에 대해 살펴볼 것이다. 여기서는, 후자 task만으로 GPT-3를 평가할 것이다.
GPT-3의 few-shot 입력값으로 1개에서 5개까지의 (단어 정의와 사용 예시를 포함한) 시연을 제공할 것이다.
GPT-3의 few-shot이 생성한 모든 문장 모두 정확히 혹은 그럴듯하게 사용했다. 다시 말해, GPT-3의 few-shot은 새로운 단어를 문장에 사용하는 것에 능숙한 것으로 보였다.

the ability to learn and utilize new words, for example, using a word in a sentence after seeing it defined only once, or conversely inferring a word's meaning from only one usage.
we give GPT-3 the definition of a nonexistent word, such as "Gigammuru", and then ask it to use it in a sentence. We provide one to five previous examples of a nonexistent word being defined and used in a sentence, so the task is few-shot in term of previous examples of the broad task and one-shot of the specific word.
In all cases the generated sentence appears to be a correct or at least plausible use of the word.
Overall, GPT-3 appears to be at least proficient at the task of using novel words in a sentence.
3.9.6. Correcting English Grammar
"Poor English Input" <sentence>\n Good English Output: <sentence>" 형태의 프롬프트로 few-shot setting 성능을 평가했다. 이때, 5개 이상의 시연을 제공했다.

we test this with GPT-3 in the few-shot setting by giving prompts of the form "Poor English Input" <sentence>\n Good English Output: <sentence>". We give GPT-3 one human-generated correction and then ask it to correct 5 more.
4. Measuring and Preventing Memorization Of Benchmarks
광범위한 인터넷 dataset을 사용하기 때문에, benchmark 테스트 데이터와 겹치는 부분이 존재할 수 있다. 즉, 오염 문제가 발생할 수 있다.
pre-training dataset 규모가 더욱 커질 것이므로, 오염 문제에 더 많은 관심을 갖고 지켜봐야 한다.
GPT-3는 Common Crawl의 광범위의 dataset을 사용하여, 잠재 오염과 암기 가능성이 높아졌다. 하지만, 다행히도, 엄청난 양의 dataset 덕분에, GPT-3 175B도 학습 데이터를 과대적합시키지 못했다.
그리므로, 오염 문제는 빈번하나, 그로 인한 성능 왜곡은 크게 없을 것으로 기대했다.
각 benchmark마다, pre-training dataset과 겹칠 가능성이 있는 모든 예시를 제거한 'clean' 버전을 만들었다. 전처리 과정을 간단히 설명하자면, 13-gram 이상으로 겹치는 모든 예시를 제거했다. clean 버전의 목표는 매우 보수적으로 오염 가능성이 있는 모든 예시를 표시하는 것이다.
이후 clean benchmark와 기존 benchmark의 성능을 비교해봤다.
비록 잠재적 오염 가능성이 높아도, 대부분의 경우 성능 변화가 미미했다. 뿐만 아니라, 오염 수준과 성능 변화 간의 명확한 관계를 찾지 못했다. 그래서, 두 가지 중 하나라고 결론을 내렸다. 1. 보수적인 분석이 false positive(=오염이 아닌데 오염이라고 판단한 것)를 많이 만들어 부정확한 결과를 가져왔다. 2. 오염이 큰 영향을 주지 않는다.
이번 오염 분석의 한계점은 clean 버전과 기존 버전 간의 분포 차이가 없음을 확신하지 못한다는 것이다. 이는 암기가 성능에 영향을 준다는 가능성을 아직도 열어줄 뿐만 아니라, 분포의 이동이 문제 난이도를 하향시킨다는 가능성도 열어준다. 하지만, 분포 이동 가능성은 0에 수렴하고, 작은 모델에도 성능 차이가 거의 없는 것을 보면 암기 가능성도 없어 보인다.
Since our training dataset is sourced from the internet, it is possible that our model was trained on some of our benchmark test sets.
given the increasing scale of pretraining datasets, we believe this issue is becoming increasingly important to attend do.
GPT-3 operates in somewhat different regime. On the other hand, the dataset and model size are about two orders of magnitude larger than those used for GPT-2, and include a large amount of Common Crawl, creating increased potential for contamination and memorization. On the other hand, precisely due to the large amount of data, even GPT-3 175B does not overfit its training set by a significant amount.
Thus, we expect that contamination is likely to be frequent, but that its effects may not be as large as feared.
For each benchmark, we produce a 'clean' version which removes all potentially leaked examples, defined roughly as examples that have 13-gram overlap with anything in the pretraining set (or that overlap with the whole example when it is shorter than 13-gram). The goal is to very conservatively flag anything that could potentially be contamination.
We then evaluate GPT-3 on these clean benchmarks, and compare to the original score.
Although potential contamination is often high, in most cases performance changes only negligibly, and we see no evidence that contamination level and performance difference are correlated. We conclude that either our conservative method substantially overestimated contamination or that contamination has little effect on performance.
An important limitation of our contamination analysis is that we cannot be sure that the clean subset is drawn from the same distribution as the original dataset. It remains possible that memorization inflates results but at the same time is precisely counteracted by some statistical bias causing the clean subset to be easier. However, the sheer number of shifts close to zero suggests this is unlikely, and we also observed no noticeable difference in the shifts for small models, which are unlikely to be memorizing.
5. Limitations
1. 텍스트 생성 성능이 전반적으로 향상됐지만, 비슷한 문장을 반복 생성하거나, 일관성을 유지하지 못하거나, 모순되는 문장을 생성하거나, 비논리적인 문장을 생성하는 현상들이 자주 관찰됐다.
단어가 같은 의미로 사용되었는지 등의 비교 task(=WiC, ANLI)에도 무작위 수준의 성능(~33%)을 보였다.
2. GPT-3의 단방향 구조는 한계가 존재한다. 단방향 구조는 "양방향 문맥을 필요로 하는 task의 성능 감소"라는 위험을 감수해야 하기 때문이다. 이전 연구는 대규모 양방향 모델이 fine-tuning에 더 강할 것이라고 추측했기 때문에, 대규모 양방향 모델의 zero-, few-shot learning 시도는 좋은 연구 방향이다.
3. 대규모 LM-like 모델의 근본적인 한계는 바로 현재 pre-training 목표 함수(=Likelihood, MLM)의 한계다. 현재 목표 함수는 모든 target token에 같은 가중치를 부여한다. 즉, token 중요도에 따른 가중치 부여 등의 세세한 레발링이 없다. 뿐만 아니라, 현재 목적 함수는 모든 task를 예측 task로 강제한다. (예측보단 목표 지향 행동(?)을 하는 언어 시스템이 더 유용하다고 생각하는 것은 자연스럽다.) 마지막으로, 대규모 언어 모델은 다른 영역(=비디오, 현실과 상호작용)을 경험하지 않았다. 때문에, 세상에 대한 많은 지식이 부족하다. 위와 같은 이유로, 현재 목표 함수는 한계에 도달했다고 볼 수 있고, 다른 방법과의 접목으로 만든 더 좋은 목표 함수가 필요하다.
4. 언어 모델의 또 다른 한계는 심각한 학습 효율이다. 높은 학습 효율은 장려되야 하는 연구 방향이며, 이는 다른 영역의 지식 습득을 통해 혹은 구조적(=알고리즘적) 개선을 통해 해소될 수 있다.
5. few-shot이 어떤 원리로 작동하는지 즉, 새롭게 task를 학습하는 것인지 혹은 기존의 학습된 지식으로 task를 인지하고 적응하는 것인지 불확실하다. few-shot의 작동 원리 이해는 매우 중요한 영역이다.
6. 또 다른 개선 사항은 바로 매우 비싼 추론 비용이다. 해결 방법 중 하나는 바로 증류(=distillation)다. 특히, GPT-3와 같은 대규모 언어 모델은 매우 광범위한 스킬을 가지고 있지만, 대부분의 지식이 task에 필요 없다. 때문에 공격적인 증류를 통해 모델을 크게 축소시킬 수 있다.
7. 마지막으로, 출력값을 예측하기 매우 어렵다는 한계점이 있다. 새로운 입력값에 따른 출력값이 매우 다양하다. 즉, 인간보다 넓은 출력 분산 범위를 보여준다. 뿐만 아니라, 학습 데이터의 편견 또한 가지고 있어, 매우 편파적인 출력값을 생성하는 결과를 야기할 수 있다.
On text synthesis, although the overall quality is high, GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs.
it does little better than chance when evaluated one-shot or even few-shot on some "comparison" tasks, such as determining if two words are used the same way in a sentence, or if one sentence implies another.
GPT-3 has several structural and algorithmic limitations, which could account for some of the issues above.
our design decision comes at the cost of potentially worse performance on tasks which empirically benefit from bidirectionality. This may include fill-in-the -black tasks.
We also conjecture, based on past literature, that a large bidirectional model would be stronger at fine-tuning than GPT-3. Making bidirectional model at the scale of GPT-3, and/or trying to make bidirectional models work with few- or zero-shot learning, is a promising direction for future research, and could help achieve the "best of both worlds".
A more fundamental limitation of the general approach described in this paper - scaling up any LM-like model, whether autoregressive or bidirectional - is that it may eventually run into (or could already be running into) the limits of the pretraining objective. Our current objective weights every token equally and lacks a notion of what is most important to predict and what is less important. previous work demonstrate benefits of customizing prediction to entities of interest. Also, with self-unsupervised objectives, task specification relies on forcing the desired task into a prediction problem, whereas ultimately, useful language systems (for example virtual assistants) might be better thought of as taking goal-directed actions rather just making predictions.
Finally, large pretrained language models are not grounded in other domains of experience, such as video or real-world physical interaction, and thus lack a large amount of context about the world. For all these reasons, scaling pure self-supervised prediction is likely to hit limits, and augmentation with a different approach is likely to be necessary. Promising future directions in this vein might include learning the objective function from humans, a fine-tuning with reinforcement learning, or adding additional modalities
Another limitation broadly shared by language models is poor sample efficiency during pre-training.
Improving pre-training sample efficiency is an important direction for future work, and might come from grounding in the physical world to provide additional information, or from algorithmic improvements.
A limitation, or at least uncertainly associated with few-shot learning in GPT-3 is ambiguity about whether few-shot learning actually learns new tasks "from scratch" at inference time, or if it simply recognizes and identifies tasks that it has learned during training.
Synthetic tasks such as wordscrambling or defining nonsense words seem especially likely to be learned de novo, whereas translation clearly must be learned during pretraining.
understanding precisely how few-shot learning works is an important unexplored direction for future research.
they are both expensive and incovenient to perform inference on, which may present a challenge for practical applicability of models of this scale in their current form. One possible future direction to address this is distillation of large model down to a manageable size for specific tasks. Large model such as GPT-3 contain a very wide range of skills, most of which are not needed for a specific task, suggesting that in principle aggressive distillation may be possible.
Finally, GPT-3 shares some limitations common to most deep learning systems - its decisions are not easily interpretable, it is not necessarily well-calibrated in its predictions on novel inputs as observed by the much higher variance in performance than humans on standard benchmarks, and it retains the biases of the data it has been trained on. This last issue - biases in the data that may lead the model to generate stereotyped or prejudiced content.
6. Related Work
많은 연구들이 생성 혹은 task 성능을 높이기 위해, 언어 모델의 parameter 혹은 학습 계산량 증가에 초점을 맞추고 있다. 위 연구는 parameter와 계산량 둘 다 확장하는 방향으로 연구를 진행했다.
뿐만 아니라, 여러 연구에서 언어 모델의 확장과 성능 간의 관계를 체계적으로 분석해, 손실값과 자기 회귀 언어 모델 크기 간의 관계가 power-law를 따르는 것을 발견했다. 이러한 결과는 모델 크기 확장이라는 연구 유행을 만들었다.
그에 반해, 모델 성능을 유지한 채 크기를 축소하는 정반대의 연구(e.g., ALBERT)도 활발히 진행되고 있다.
이번 연구의 few-shot 접근법과는 다르지만, 이전 연구에서는 pre-trained 모델과 parameter 수정을 같이 사용해 few-shot learning을 하는 시도와, 소량의 라벨링 데이터만 필요한 준지도 학습로 fine-tuning하는 시도가 있었다.
추가로, 텍스트로 task를 설명하는 방식은 text-to-text transformer에서 연구됐다. 하지만 이번 연구와 다르게 mulit-task fine-tuning 모델에 적용됐었다.
일반성과 전이 학습 능력을 높이기 위한 또 다른 접근법에는 multi-task learning이 있다. 여러 task를 한꺼번에 fine-tuning하는 방식이다.
하지만 여전히 대량의 dataset이 필요하고 적절한 학습 방법(=fine-tuning)을 설계해야 한다. 더 넓은 task 집합을 만들어 multi-task의 활용성을 높이는 것도 중요한 연구 영역 중 하나라고 생각한다.
언어 모델의 알고리즘 혁신은 지난 2년 동안 많이 발전했다.
이러한 기술들은 task의 성능을 크게 향상시켰다. 이번 연구에서는 in-context learning 성능에 집중하고 구현 복잡도를 줄이기 위해 자기 회귀 언어 모델에 집중했다. 하지만, 최신 기술과 통합하면 GPT-3의 성능을 웃도는 결과를 낼 가능성이 높다고 생각한다.
Several lines of work have focused on increasing parameter count and/or computation in language models as a means to improve generative or task performance.
Our work focuses on scaling compute and parameters together, by straightforwardly making the neural net larger), and increases model size 10x beyond previous models that employ this strategy.
Several efforts have also systematically studied the effect of scale on language model performance, find a smooth power-law trend in loss as autoregressive language models are scaled up. This work suggests that this trend largely continues as models continue to scale up.
Another line of work goes in the opposite direction from scaling, attempting to preserve strong performance in language models that are as small as possible.
While the mechanism of our few-shot approach is different, prior work has also explored ways of using pre-trained language models in combination with gradient descent to perform few-shot learning. Another sub-field with similar goals is semi-supervised learning also explore methods of fine-tuning when very little labeled data is available.
The notion of presenting tasks in natural language was also explored in the text-to-text transformer, although there it was applied for multi-task fine-tuning rather than for in-context learning without weight updates.
Another approach to increasing generality and transfer-learning capability in language models is multi-task learning, which fine-tunes on a mixture of downstream tasks together, rather than separately updating the weights for each one.
But is still limited by the need to manually curate collections of datasets and set up training curricula. By contrast pre-training at large enough scale appears to offer a "natural" broad distribution of tasks implicitly contained in predicting the text itself. One direction for future work might be attempting to generate a broader set of explicit tasks for multi-task learning.
Algorithm innovation in language models over the last two years has been enormous
Many of these techniques provide significant gains on downstream tasks. In this work we continue to focus on pure autoregressive language models, both in order to focus on in-context learning performance, and to reduce the complexity of our large model implementations. However, it is very likely that incorporating these algorithmic advances could improve GPT-3's performance on downstream tasks.
7. Conclusion
이번 연구에서 zero-, one-, few-shot에서 강력한 성능을 보여주는 1750억 parameter 언어 모델을 선보였다.
뿐만 아니라, fine-tuning을 하지 않은 언어 모델 확장에 따른 성능 향상의 대략적인 추세를 보여줬다.
이런 결과는 대규모 언어 모델이 일반적인 언어 시스템을 개발하는데 중요한 요소임을 시사한다.
We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot and few-shot settings.
We documented roughly predictable trends of scaling in performance without using fine-tuning
these result suggest that very large language models may be an important ingredient in the development of adaptable, general language systems.