2023. 8. 28. 16:12ㆍPaper Review
Abstract
이번 연구에서는, 트랜스포머 기반의 언어 모델 성능을 다양한 크기에서 분석해볼 것이다.
모델 크기 확장으로 얻은 성능 향상은 독해 이해, 사실 확인, 혐오 표현 식별과 같은 테스크가 가장 크다. 반면에, 논리적이고 수학적인 추론 테스크가 상대적으로 낮다.
we present an analysis of Transformer-based language model performance across a wide range of model scales
Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit.
We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity.
1. Introduction
자연어 기반의 소통은 인간 혹은 AI에게 생각 (or 지식)을 효율적으로 전달해주는 수단이다. 때문에, 자연어 기반의 소통은 지능(=정보 수집)의 핵심이다. 언어의 일반성(=언어 표현의 다양성)은 입력값과 출력값을 자연어로 표현하는 방식으로 지적인 테스크를 명시할 수 있게 해준다.
자기 회귀 언어 모델링 즉, 이전 텍스트를 기반으로 다음 텍스트를 예측하는 방식은 간단하지만, (자연어로 표현된 수 많은 지적 테스크를 이해 (or 인지)할 수 있는) 강력한 목표 함수다.
하지만, 이러한 목표 함수는 구체적인 목표 함수의 근사 함수에 불과하다. 왜냐하면 구체적인 목표에 맞는 측면에서 예측하지 않고, 모든 것을 시퀀스로 예측하기 때문이다. 하지만, 신중하고 적절히 모델을 다루면, 인간의 지능을 가진 강력한 툴이 될 수 있으러가 믿는다.
언어 모델을 지능의 요소로 활용하는 연구는 초기 연구(텍스트를 제한된 대역폭의 통신 채널에 텍스트를 전송하는 연구)와 대조된다.
Shannon은 언어 모델의 cross entropy을 측정하는 것과 압축을 측정하는 것은 동일함을 보이면서, 통계적 언어 모델링과 압축을 연결시켰다.
Shannon은 (모델 복잡도와 연관 있는) 텍스트 통계 테이블을 통해 언어 모델을 실제 데이터에 적용시켰다. 이는 텍스트 압축을 향상시킴과 동시에 더 현실적인 텍스트를 생성한다.
Shannon은 충분히 복잡한 모델(더 좋은 텍스트 통계 테이블?)은 사람의 소통을 모방할 수 있다고 주장했다.
(무슨 말인지 정확히 이해되지 않는다ㅜㅜ)
그 후 계산 속도가 기하급수적으로 발전하면서, 언어 모델의 관점이 (압축에서) capacity(=its ability to fit a wide variety of functions)와 예측 능력으로 이동했다.
1990년대 ~ 2000년대, n-gram 모델이 크기 확장과 이로 인한 성능 향상을 보였다. 하지만, 텍스트 길이가 길어질수록 통계적으로 연산적으로 매우 비효율적으로 변해, 불가피하게 텍스트 길이를 제한했다. 이는 모델링할 수 있는 언어의 지식 크기를 제한한다.
지난 20년간, 언어 모델은 (언어 구조를 임의적으로 파악하는 즉, 언어의 통계적 지식을 임의의 함수로 표현할 수 있는) 인공 신경망을 통해 많이 발전해왔다. 이 발전은 모델 크기 확장과 신경망 구조에 기반한다.
이전 연구에서는 트랜스포머와 RNN의 모델 크기와 cross-entropy 손실값의 관계가 power-law를 따른다는 것을 발견했고, 이러한 예측은 GPT-3를 통해 기정 사실화가 됐다.
이번 연구에서는, SOTA 언어 모델 학습 프로토콜을 설명하고 2800억 파리미터 모델 Gopher를 발표할 것이다.
Gopher는 81% 테스크에서 현재 SOTA 성능을 보이며, knowledge-intensive(=외부 지식 없이는 해결하기 힘든) task에 강점을 보인다.
뿐만 아니라, 편견과 혐오에 관해 조사할 것이며, 특히 모델 크기 확장이 이러한 속성에 어떤 영향을 주는지 집중적으로 분석할 것이다.
Natural language communication is core to intelligence, as it allows ideas to be efficiently shared between human or artificially intelligent systems. The generality of language allows us to express many intelligence tasks as taking in natural language input and producing natural language output.
Autoregressive language modeling - predicting the future of a text sequence from its past - provides a simple yet powerful objective that admits formulation of numerous cognitive tasks.
However, this training objective is only an approximation to any specific goal, or application, since we predict everything in the sequence rather than only the aspects we care about. Yet if we treat the resulting models with appropriate caution, we believe they will be a powerful tool to capture some of the richness of human intelligence.
Using language models as an ingredient towards intelligence contrasts with their original application: transferring text over a limited-bandwidth communication channel. Shannon's Mathematical Theory of Communication linked the statistical modelling of natural language with compression, showing that measuring the cross entropy of a language model is equivalent to measuring its compression rate. Shannon fit early language models to real data via precomputed tables of text statistics relating model complexity to improved text compression alongside more realistic text generation.
Shannon posits that a sufficiently complex model will be resemble human communication adequately
From their pen-and-paper origins, language models have transformed in capacity and predictive power by the exponential rise in compute. (capacity=its ability to fit a wide variety of functions), n-gram model saw increases in scale and better smoothing approaches.
However n-gram models become statistically and computationally inefficient as the context length is increased, which limits the richness of language they can model.
In the past two decades language models have progressed to neural networks that capture the structure of language implicitly. Progress has been driven by both scale and network architecture. Previous works independently found power laws relating cross entropy loss to model size for recurrent and Transformer neural language models respectively. The empirically predicted gains to scale were realised in practice by GPT-3
In this paper, we describe a protocol for training a state-of-the-art large language model and present a 280 billion parameter model called Gopher.
We see that Gopher lifts the performance over current state-of-the-art language models across roughly 81% of tasks containing comparable results, notably in knowledge-intensive domains such as fact checking and general knowledge.
we examine model toxicity and bias with a focus on how scale influences these properties.
2. Background
언어 모델링은 임의의 텍스트의 확률을 모델링하는 것이다.
이는 토큰화 과정을 거친다. 즉, 텍스트를 정수값 토큰들로 바꾸는 과정을 말한다.
토큰화 종류에는 두 가지가 있다. open-vocabulary(=모든 문자열을 유일한 정수값 토큰으로 변경) closed-voabulary(=부분 문자열만 유일한 정수값 토큰으로 변경) 이번 연구에서는 (UTF-8 바이트 기반의 BPE인) open-vocabulary 토큰화를 사용할 것이다.
체인 법칙($P(X) = P(X_1, X_2, \cdots, X_n) = \prod_{i=0}^n P(X_i|x_{<i})$)을 통해 토큰화 시퀀스 $X$를 모델링한다.
이것이 자기 회귀 모델링이다. 각 타임 스탭마다 기존 텍스트를 기반으로 다음의 토큰을 예측하기 때문이다.
다른 모델링 방법도 존재(e.g., MLM)하지만, (성능이 좋고 간단한) 자기 회귀 모델링을 사용할 것이다.
이번 연구에서는, 편의상 언어 모델을 다음 토큰 예측하는 근사 함수로 부를 것이다.
최근 transformer 인공 신경망이 언어 모델에서 SOTA 성능을 보일 뿐만 아니라,
데이터셋, 모델 크기, 계산량을 확장시켜 성능을 향상시키는 연구 유행을 보이고 있다.
Language modelling refers to modelling the probability of text P(s) where S can be a sentence, paragraph, or document depending on the application. This is done by tokenizing the string: mapping it to a sequence of integer-valued tokens: $g(S) = X = (X_1, X_2, \cdots, X_n) \in V^n$ where $V$ is the vocabulary (a finite set of positive integers) and n is the resulting sequence length, and modelling X. Tokenization can be open-vocabulary where any string can be uniquely tokenized,
closed-vocabulary where only a subset of text can be uniquely represented,
We employ open-vocabulary tokenization via a mixture of byte-pair encoding (BPE) with a backoff to UTF-8 types.
The typical way to model the token sequence X is via the chain rule $P(X) = P(X_1, X_2, \cdots, X_n) = \prod_{i=0}^n P(X_i|x_{<i})$. This is also known as autoregressive sequence modelling, because at each time-step the future (in this case, future token) is predicted based upon the past context.
whilst there are other objectives towards modelling a sequence.
we focus on autoregressive modelling due to its strong performance and simplicity. We shall refer to language models hereon as the function approximators to perform next-token prediction.
A class of neural networks known as Transformers have demonstrated state-of-the-art language model performance in recent years.
There has been a trend of scaling the combination of training data, model size (measured in parameters) and training computation to obtain models with improved performance across academic and industrial benchmarks
3. Method
3.1. Models
이번 연구에서는, 0.44억부터 2800억 파리미터에 이르는 트랜스포머 모델 6개를 소개할 것이다.
GPT-2에서 소개한 자기 회귀 트랜스포머 구조를 사용할 것이다. 이때, 두 가지를 수정할 것이다. 1). LayerNorm 대신 RMSNorm을 사용한다. 2). absolute positional encoding 대신 Transformer-XL에서 소개한 relative positional encoding을 사용한다.
relative positional encoding은 학습 단계에서 사용한 시퀀스 길이보다 더 긴 시퀀스 길이를 평가할 수 있게 해준다. 뿐만 아니라, 기사와 책의 모델링 능력을 향상시켜준다.
In this paper, we present results on six Transformer language models ranging from 44 million to 280 billion parameters.
We use the autoregressive Transformer architecture detailed in GPT-2 with two modifications: we use RMSNorm instead of LayerNorm and we use the
relative positional encoding scheme
from Transformer-XL rather than absolute positional encodings. Relative encodings permit us to evaluate on longer sequences than we trained on, which improves the modelling of articles and books. We tokenize the text using SentencePiece with vocabulary of 32000 and use a byte-level backoff to support open-vocabulary modelling.
3.2. Training
3000억 토큰을 2048개 토큰으로 나눠 모든 모델을 학습시킨다.
1). Adam 최적화 함수를 사용한다. 2). $10^{-7}$ lr를 maximum lr까지 1500 step 동안 warm-up 한 후 cosine shedule를 사용해 기존 10배로 lr를 줄인다. 3). 모델 크기가 증가하면, maximum lr를 줄이고 batch의 토큰 개수를 늘린다. 참고로, Gopher의 batch 크기는 학습 도중 300만에서 600만으로 증가한다. 4). (global gradient norm보다 높으면, gradient를 1로 줄이는) gradient clipping을 사용한다. 참고로, 7.1B 모델과 Gopher일 때, 0.25로 줄어 안정성을 항샹시켰다.
7.1B 보다 작은 모델은 (float32 파리미터와 float16 activations인) mixed preicision를 사용한다.
그에 반해, 7.1B 모델과 Gopher는 둘 다 float16을 사용한다. 안정성을 위해 확률적 반올림(예를 들어, 1.6은 40%로 1, 60%로 2가 된다.)으로 float16 파리미터를 최적화할 것이다. 하지만, 위 방법은 mixed precision의 학습 성능에 비해 낮다는 것을 발견했다.
We train all models for 300 billion tokens with a 2048 token context window using the Adam optimiser. We warm-up the learning rate from $10^{-7}$ to the maximum learning rate over the first 1500 steps, and then decay it 10x using a cosine schedule. As we increase model size, we decrease the maximum learning rate and increase the number of tokens in each batch. Furthermore, we increase Gopher's batch size from three to six million tokens per batch (almost 1000 to 3000 batch size). We clip gradients based on the global gradient norm(=the norm of the gradient with respect to all model parameters) using a clipping value of 1. However, for the 7.1B model and for Gopher we reduce this to 0.25 for improved stability.
Models smaller than 7.1B are trained with mixed precision float32 parameters and bfloat16 activations, while 7.1B and 280B use bfloat16 activations and parameters. bfloat16 parameters are updated using stochastic rounding to maintain stability. We subsequently found that stochastic rounding does not fully recover mixed precision training performance.
3.3. Infrastructure
Gopher의 float16 파라미터와 float32 optimizer state는 2.5TiB 메모리를 잡아먹는다. 이 문제를 해결하기 위해, optimizer state 분할(=ZeRO), 모델 병렬화(=tensor parallelism), 그리고 rematerialisation(=메모리에 값을 저장하는 대신 다시 계산하는 방법)을 사용해 메모리 사용량을 줄일 것이다. 데이터 병렬화(=ZeRO)와 모델 병렬화는 (TPU 간의 빠른 통신으로) 낮은 overhead를 보여준다. 참고로, Gopher를 학습할 때, 10% overhead를 보여준다.
더 나아가, 통신 비용이 매우 낮은 파이프라인 병렬화도 사용할 것이다. 요약하자면, 세 가지 병렬화 기법을 활용해 Gopher를 학습시킬 것이다.
The half-precision parameters and single-precision Adam state for Gopher occupy 2.5TiB, which far exceeds the 16GiB of memory available on each TPUv3 core. To address these memory concerns, we use optimiser state partitioning (ZeRO), model parallelism, and rematerialisation(=메모리에서 값을 로드하는 대신 값을 다시 계산하여 시간을 절약하는 컴파일러 최적화다) to partition the model state and reduce the activations so they fit in TPU memory.
We find that both data and model parallelism are low-overhead on TPUv3s due to their fast cross-chip communication and only incur a 10% overhead when training Gopher.
However, pipelining is an efficient parallelism method on commodity networks due to its low communication volume, so is well suited to connecting multiple TPU pods. In summary, we train Gopher by using model and data parallelism within TPU pods and pipelining across them.
3.4. Training Dataset
MassiveText를 통해 모든 모델을 학습시킬 것이다. MassiveText는 웹 페이지, 책, 뉴스 기사, 코드 등 여러 종류의 텍스트를 가지고 있는 영어 기반 데이터셋이다.
데이터 전처리에는 품질 필터링, 반복 텍스트 제거, 비슷한 문서 제거, 테스트 데이터와 매우 비슷한 문서 제거 등의 과정을 거친다.
이러한 전처리 과정은 downstream 성능 향상에 도움을 주다. 그 중에서도, 데이터 품질이 중요하다.
300B 토큰으로 Gopher를 학습시키기 때문에, MassiveText에서 데이터를 샘플링해야 한다.
샘플링 방법은 다음과 같다. 텍스트 종류(e.g., books, news) 별로 전체 학습 데이터에 할당될 비율을 샘플링한다. 참고로, downstream 성능을 극대화하기 위해, 비율을 추가 조율할 것이다. 비율이 가장 높은 텍스트 종류는 MassiveWeb으로, C4와 같은 web-text 데이터셋에 비해 downstream 성능을 더욱 더 향상시켜준다.
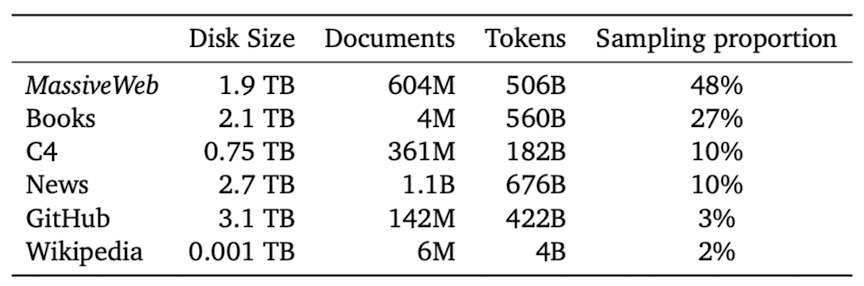
We train the Gopher family of models on MassiveText, a collection of large English-language text datasets from multiple sources: web pages, books, news articles, and code.
Our data pipeline includes text quality filtering, removal of repetitious text, deduplication of similar documents, and removal of documents with significant test-set overlap. We found that successive stages of this pipeline improve language model downstream performance, emphasising the importance of dataset quality.
Since we train Gopher on 300B tokens, we sub-sample from MassiveText with sampling proportions specified per subset(books, news, etc). We tune these sampling proportions to maximise downstream performance. The largest sampling subset is our curated web-text corpus MassiveWeb, which we find to improve downstream performance relative to existing web-text datasets such as C4.
4. Results
152개의 task에 대한 Gopher 성능을 측정할 것이다. (물론 그 외의 모델도 측정할 것이다.) 뿐만 아니라, 1). SOTA 언어 모델(e.g., GPT-3, Jurassic-1, Megatron-Turing NLG), 2). SOTA 지도 학습 모델 그리고 3). 사람과 성능 비교를 할 것이다.
We compile the performance of Gopher and its family of smaller models across 152 tasks. We compare these results to prior state-of-the-art (SOTA) performance for language models, supervised approaches which make use of task-specific data, and human performance where available.
4.1. Task Selection
언어 모델링, 수학, 일반 추론(=상식 추론), 논리적 추론(=어려운 추론), 일반 지식, 사실 확인(=근거에 기반해 주장의 사실 여부 판단), 윤리학 & 인문학(e.g., 역사, 철학), 과학/기술/공학/의약, 독해력(=지문에 관한 질문)으로 언어 모델 성능을 분석할 것이다.
목표(=target) 텍스트의 확률을 추정하는 task만 선정했다. 지식과 추론 능력 수준을 확인할 수 있는 일반적인 인터페이스라고 생각하기 때문이다. 언어 모델링 task는 BPB로 평가할 것이며, 그 외 객관식 task는 정답의 추론 확률로 평가할 것이다.
공정한 평가를 위해, 테스트 데이터와 매우 비슷한 학습 데이터셋의 문서는 걸러냈다.
We build a profile of language model performance that spans language modelling, reading comprehension, fact checking, question answering, common sense, MMLU, BIG-bench.
We select tasks that require the model to estimate the probability of target text as we find this to be general interface that supports the probing of knowledge and reasoning capabilities. For language modelling tasks we calculate the bits per byte (BPB).
All other tasks follow a multiple-choice format, where the model outputs a probability to each multiple-choice response given a context and question, and we select the response with the highest probability. Here, we measure the accuracy of a correct response.
We filter out training documents that are very similar to test-set instances for tasks that were created before MassiveText.
4.2. Comparisons with State of the Art
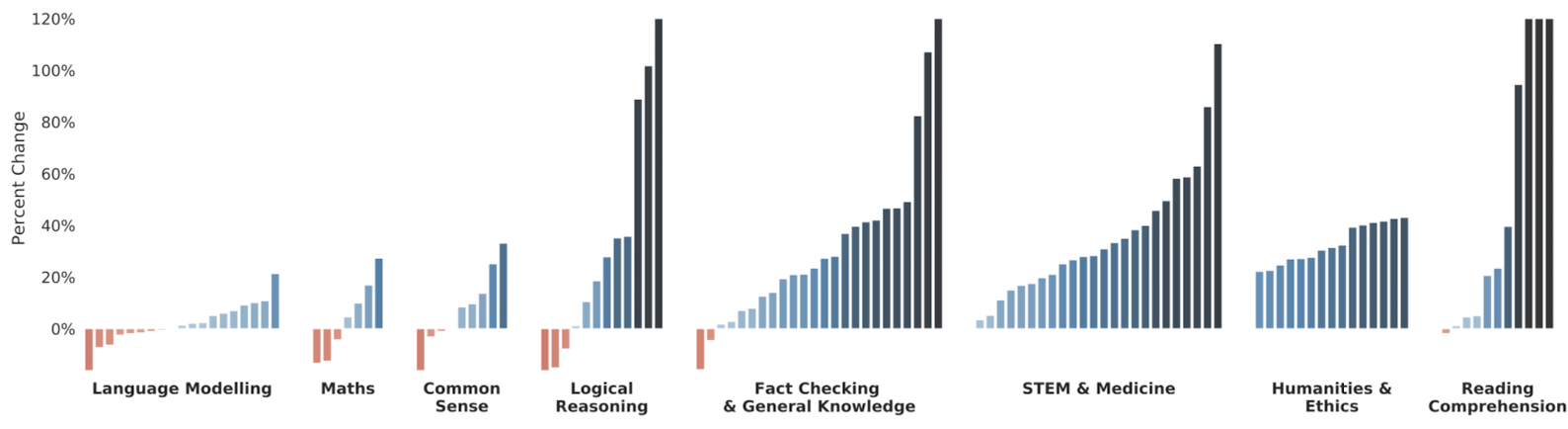
124가지 task로 Gopher와 SOTA 언어 모델 간의 성능 비교를 진행한 결과, Gopher가 100가지 task에서 더 높은 성능을 보였다.
독해력, 윤리학 & 인문학, 과학/기술/공학/의약에서 가장 높은 성능 향상을 보였으며, 사실 확인이 그 다음으로 높은 성능 향상을 보였다.
그에 반해, 일반 추론, 논리적 추론, 수학은 미미한 성능 향상을 보였을 뿐만 아니라 몇 가지 task에서 성능 감소를 보였다.
결론적으로, 지식 기반 task는 높은 성능 향상을 보인 반면, 추론 기반 task에서는 미미한 성능 향상을 보였다. (뇌피셜, 지식 기반 task가 높은 이유는 27%의 book과 10%의 news 때문이라고 생각한다. 참고로, GPT-3의 book은 16%다.)
언어 모델링 task에서는, Jurassic-1가 GPT-3와 비슷한 파라미터 개수를 가지고 있지만 GPT-3 보다 높은 성능을 보였다. 큰 사전으로 학습을 진행한 것이 이유일 수 있다
Gopher가 책과 기사에 기반한 언어 모델링 task에서는 Jurassic보다 높은 성능을 보였다. 이러한 성능 향상은 책 데이터의 많은 학습량이 이유일 수 있다.
독해력 task에서는, RACE-m와 RACE-h를 중점적으로 봤다. Gopher는 2가지 task에서 기존 SOTA 언어 모델보다 높은 성능을 보였다.
7.1B 이하 모델들에서는 낮은 성능을 보여줬다. 즉, 데이터만으로는 성능 차이를 못낸다. 이는 데이터와 모델 크기의 조합이 중요하다는 것을 시사한다.
대표적인 일반 추론 task: Winogrande, HellaSwag, PIQA에서 Gopher는 Megatron-Turing NLG를 작은 차이로 앞섰다. 하지만, 사람과는 큰 성능 차이를 보인다.
낮은 수학 task 성능을 보면, 언어 모델은 추론 능력에 한계가 있음을 시사한다.
사실 확인 task는 잘못된 정보 전달이라는 문제와 연관이 깊다. Gopher가 FEVER(근거 제공)에서 지도 학습 SOTA 모델보다 더 좋은 성능을 보였다. 뿐만 아니라, 모델 크기가 커질수록 근거 여부와 상관 없이 성능이 향상된다. 하지만, 모델 크기가 UNKOWN과 거짓을 구분하는데 도움을 주진 않는다. 이는 잘못된 정보에 대한 깊은 이해도 보단 더 많은 사실(=지식)이 성능에 도움을 줬다는 것을 의미한다.
MMUL Benchmark는 여러 과목 시험들로 구성되어 있다. 언어 모델의 기존 성능은 높였지만, 전문가의 성능보단 뒤 떨어진다. 하지만, 사람의 예측보다 빠르게 성능 향상을 시키고 있다.
Gopher는 광범위한 task에서 언어 모델의 기존 성능을 향상 시켰다. 하지만, 추론 task에서는 미미한 성능 항샹을 보였으며 이는 LLM의 한계임을 암시한다.
Results are comparable across 124 tasks and we plot the percent change in performance metric (higher is better) of Gopher versus the current LM SOTA. Gopher outperforms the current state-of-the-art for 100 tasks (81% of all tasks).
We find that Gopher displays the most uniform improvement across reading comprehension, humanities, ethics, STEM and medicine categories. We see a general improvement on fact-checking. For common sense reasoning, logical reasoning, and maths we see much smaller performance improvements and several tasks that have a deterioration in performance. The general trend is less improvement in reasoning-heavy tasks and a larger and more consistent improvement in knowledge-intensive tests.
For language model benchmarks, we expand the relative performance results of Gopher versus the current 178B SOTA model Jurassic-1 and 175B GPT-3. Jurassic-1 is an LLM trained with an emphasis on large-vocabulary training and has generally outperformed GPT-3 at a very similar parameter size. We see Gopher does not outperform state-of-the-art on 8 of 19 tasks, possibly due to a poor tokenizer representation for numbers. Gopher demonstrates improved modelling on 11 of 19 tasks, in particular books and articles. This performance gain may be due to the heavy use of book data in MassiveText, with a sampling proportion of 27% in total.
We highlight two reading comprehension tasks RACE-m and RACE-h.
we see Gopher extend upon the current LM SOTA for high-school reading comprehension and the middle-school comprehension accuracy. Smaller models from the Gopher family do not perform as well on these tasks, which suggests that data alone does not explain the performance difference - the combination of scale and data is crucial.
For some of the most well-studied common sense reasoning tasks: Winogrande, HellaSwag and PIQA, all LM approaches trail human-level performance considerably.
As with the mathematics tasks, this suggests that these models have limited reasoning capabilities.
We next highlight fact-checking. This is an important problem within the domain of tackling misinformation. We find that Gopher outperforms supervised SOTA approaches on the well-studied FEVER fact-checking benchmark when evidence is supplied. We see across model sizes that scale improves both the checking of facts given gold evidence alongside the 'closed book' checking of facts with a claim only. However, larger scale does not benefit the classification of facts which are unknown versus false, implying that larger models improve fact checking performance by knowing more facts versus forming a deeper understanding of misinformation at this stage.
we display the average accuracy across the 57 tasks in MMLU. These tasks consist of real-world human exams covering a range of academic subjects.
Whilst this lifts the known performance of the pure language-model approach, it still trails the estimated human expert performance.
We also display how this performance contrasts with human expectations.
We conclude that Gopher lifts the baseline performance of a language-model approach across a wide set of tasks.In some settings.
However for a few categories of tasks (e.g., mathematical reasoning and common reasoning), there is less of an improvement and this may indicate a limitation to the large-scale language model approach.
4.3. Performance Improvements with Scale
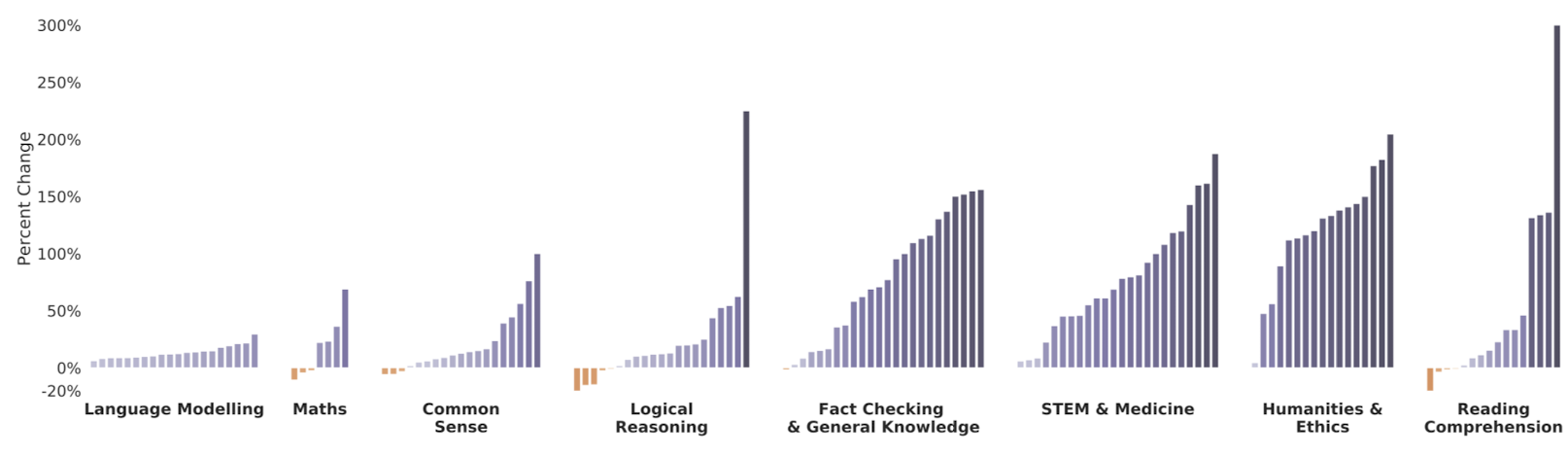
Gopher family 모델들은 모두 같은 데이터셋으로 학습하기 때문에, 모델 크기와 계산량의 효과를 정확히 측정할 수 있다.
우선, Gopher 성능과 7.1B 이하의 모델 중 최고 성능을 152가지 task로 비교해볼 것이다.
일반적으로, Gopher가 높은 성능을 보였다. 미미한 성능 향상을 보인 task는 모델 크기 증가가 성능에 영향이 주지 않거나 작은 모델에서도 높은 성능을 가진다.
이제부터 모델 크기에 따른 성능 향상 정도를 살펴보겠다.
의약/과학/기술 그리고 인문학에서 가장 높은 성능 향상을 보였다. 이는 SOTA 언어 모델 성능 비교와 같은 결과다.
일부 task(e.g., Figure of Speech Detection, Logical Args, Marketing, Medical Genetics, )에서는 모델 크기 확장으로 인한 엄청난 성능 향상을 보였다. 뿐만 아니라, 이전 연구에서 모델 크기 확장에 따른 성능 감소를 보인 task(=TruthfulQA)에서도 성능 향상을 보였다.
이는 모델 크기 확장이 일부 task에게는 매우 중요하다는 것을 시사한다.
반면에, 수학, 논리적 추론, 일반 추론에서 미미한 성능 향상을 보였다.
이는 수학 혹은 논리적 추론의 속성을 가질 경우, 모델 크기 확장으로 인한 성능 향상을 기대하기 힘들다는 것을 시사한다.
언어 모델링에서는 가장 낮은 성능 향상을 보였는데, 이는 BPB로 성능 측정을 했기 때문이다.
모델 크기 확장은 대부분의 task의 성능 향상에 매우 중요한 요소이지만, 모델 크기 확장은 무조건 task의 성능 향상을 이끄는 것은 아니다.
모델 크기 확장 효과와 SOTA 언어 모델 간의 비교 결과를 통해, 모델 크기 확장 및 데이터가 Gopher의 강력한 성능 향상에 엄청난 기여를 하고 있음을 알 수 있다.
Because the Gopher family of models are all trained on the same dataset for the same number of tokens, this allow us to isolate the effect of scaling parameters and training compute for each task.
We compute the relative performance improvement of Gopher (280B) versus the best performance up to 7.1B over all 152 tasks.
Gopher outperforms the best smaller model's performance. Small gains come from either scale not improving results substantially or the smaller models already being very performant.
Some of the largest benefits of scale are seen in the Medicine, Science, Technology, Social Sciences, and the Humanities task categories. These same categories are also where we see the greatest performance improvement over LM SOTA.
for Figure of Speech Detection from BIG-bench we obtain the largest gains-a 314% increase.
Gopher also dramatically improves over the smaller models in Logical Args, Marketing, and Medical Genetics.
For the TruthfulQA benchmark we find performance improvement with scale.
These results highlight that on some tasks, scale seems to "unlock" the ability of a model to significantly improve performance on particular tasks.
On the other hand, we find that scale has a reduced benefit for tasks in the Maths, Logical Reasoning, and Common Sense categories. Our results suggest that for certain flavours of mathematical or logical reasoning tasks, it is unlikely that scale alone will lead to performance breakthroughs.
While language modelling tasks see the smallest average improvement, this is due to the performance metric measured in BPB rather than accuracy
We conclude that while model scale plays an important role for improvements across the vast majority of tasks, the gains are not equally distributed. Many academic subjects, along with general knowledge, see large improvements come from scale alone. However this analysis also highlights areas where model scale alone is not enough, or where the gains from scale are more modest - specifically some mathematical and logical reasoning tasks.
By combining these scaling results with the comparisons of Gopher to LM SOTA, we see that scale and dataset are both contributing to Gopher's strong performance in these domains.
5. Toxicity and Bias Analysis
언어 모델 확장이 유해 행동에 미치는 영향에 대해 살펴볼 것이다.
4가지 관점(혐오 표현 생성, 혐오 표현 판별, 편견(=distributional biases), 방언)에서 분석할 것이다.
현업에서 사용하고 있는 일반적인 평가 지표를 사용할 것이다. 참고로, 이러한 평가 지표는 현계점이 존재한다.
Alongside the benefits of scaling language models, it is crucial to analyse how scale impacts potentially harmful behaviour.
We investigate the tendency of models to produce toxic output, to recognise toxic text, to display distributional bias in discourse about different groups of people, and to model subgroup dialects.
We choose evaluations and metrics which are commonly used in the field. However, various work has discussed the limitations of current metrics and evaluations and our analysis has uncovered further caveats.
5.1. Toxicity
5.1.1. Generation Analysis
유해 프롬프트 기반 생성 텍스트의 혐오 점수를 Perspective API로 측정할 것이다. 이때, RTP에서 샘플링해 유해 프롬프트를 만든다.
(뿐만 아니라, 유해 프롬프트 없이 (즉, No prompt) 생성된 텍스트의 혐오 점수도 측정할 것이다.)
유해 프롬프트 기반 생성을 통해, 모델이 프롬프트를 어떻게 활용하는지 분석할 수 있다.
유해 프롬프트가 주어진 경우, 프롬프트의 혐오 점수가 증가할수록, 크기가 큰 모델은 영향을 더 받는다. 이는 파라미터 개수가 증가할수록 모델은 프롬프트와 유사한 것을 생성하는 경향이 증가한다.
유해 프롬프트가 주어지지 않은 경우, 생성 텍스트의 혐오 점수는 낮고, 모델 크기 확장에 따른 혐오 점수 증가는 보이지 않았다. 이는 모델이 학습 데이터의 혐오성을 활용하지 않음을 의미한다.
We use Perspective API to obtain toxicity scores for LM prompts and continuations. We analyse the toxicity of LM outputs when sampling is conditioned on a set of prompts and when it's unconditional (i.e. unprompted). Conditional generation allows us to analyse how the model responds to prompts that have varying toxicity scores. Prompts are from the RealToxicityPrompts (RTP) dataset.
When prompted, as the input toxicity increases, larger models respond with greater toxicity, This suggests that more parameters increase the model's ability to respond like-for-like to inputs.
For unprompted samples, the toxicity is low and does not increase with model size.
when unprompted, the LM does not amplify training data toxicity.
5.1.2. Classification Analysis
few-shot에서 혐오 표현 판별 성능을 Civilcomments 데이터셋으로 측정해볼 것이다.

측정 결과, 판별 정확도가 모델 크기에 비례한다.
더 나아가, LLM이 특정 집단의 편견을 가지고 있는지 확인하기 위해, 280B 모델로 분석해봤다.
(e.g., 흑인 편견을 가지고 있으면, 흑인 인종차별 발언을 혐오 발언으로 분류하지 않을 수 있다.)
그 결과, 모델이 다양한 방식으로 특정 집단에 치우쳐 있음을 발견했다.
이는 언어 모델이 판별에 강력함과 동시에, 모든 집단에 공정하지 않음을 시사한다.
이러한 편향이 완화되도록 많은 연구가 진행되어야 할 필요가 있다.
We evaluate the model's ability to detect toxic text in the few-shot setting on the CivilComments dataset.
We observe that the model's ability to classify text for toxicity increases with scale in few-shot settings.
we further explore whether large language models used for few-shot toxicity classification exhibit subgroup bias. We measure unintended classifier bias using the 280B model and find the model is prone to bias against subgroups in different ways.
Thus, while language models can be a powerful tool for few-shot classification, outcomes are not necessarily fair across subgroups. More work is needed to understand how to best mitigate these biases.
5.2. Distributional Bias
이번 연구에서 살펴볼 편견은 distributional biases다. 이는 단일 텍스트에서는 보이지 않지만, 여러 텍스트를 보면 보이는 편견을 말한다.
(e.g., 모델이 특정 직업(e.g., 간호사)과 여자를 매우 밀접하게 연관시키는 경우)
이러한 편견은 모델에게 표현적으로 또는 할당적(?)으로 부정적인 영향을 준다.
3가지 방식으로 Gopher의 편견 정도를 분석할 것이다. 1). 성별과 직업 간의 고정 관념, 2). 집단의 감정(or 정서) 분포 3). 방언의 PPL
이번 연구를 통해, 모델 크기 확장이 편견 제거에 도움이 되지 못함을 발견했다.
나아가, cross-entropy로 학습된 모델은 학습을 통해 학습 데이터에 내제돼 있는 편견이 반영됐을 거라 생각한다.
We define distributional biases as biases which are not apparent in a single sample, but emerge over many samples.
it can be problematic if the model disproportionately associates women with certain occupations.
distributional biases in language models can have both negative representational impacts and allocational impacts.
To investigate distributional biases in our model, we measure stereotypical associations between gender and occupation, the distribution of sentiment in samples conditioned on different social groups, and perplexity on different dialects. Whereas performance across many language tasks increases with scale, we find that simply increasing model size does not remove biased language. Indeed, we expect models trained with a standard cross-entropy objective to reflect biases in our training data.
5.2.1. Gender and Occupation Bias
성별과 직업 편견을 2가지 평가 방법으로 분석해볼 것이다.
1). 직업 관련 텍스트 이후, 성별 관련 단어가 나올 확률을 측정한다. 2). Winogender dataset으로 평가한다.
Gender Word Probability: 직업 관련 텍스트 이후 생성될 수 있는 성별 단어의 다양성 정도를 다음과 같은 성별 편견 평가 지표로 측정할 것이다.
(즉, 직업 관련 텍스트 이후, 여러 성별 단어가 생성될 수 있다면 편견이 없는 것이고, 특정 성별의 단어만 생성될 수 있다면 편견이 있는 것이다.)
"{occupation} was a"와 같이 프롬프트를 설계하고, 프롬프트 이후 남성과 여성 관련 단어의 생성 확률을 비교할 것이다.
평가 결과, 모델 크기와 편견 정도 간의 상관관계는 보이지 않았다. 더 나아가, 의미 없는 프롬프트 변경(was → is)에도 기존 결과와 차이를 보였다. (이는, 편견이 없거나, 평가 방법이 잘못됨을 시사한다.)
Winogender: zero-shot에서 Winogender 데이터셋으로 평가를 다음과 같이 진행한다. 선지 중 어떤 것이 대명사가 무엇을 지칭하는지 모델이 유추한다.
(e.g., 프롬프트 = we input “The technician told the customer he had completed the repair. ‘He’ refers to the {technician/customer}”)
이때, 편견 없는 모델은 모든 성별에서 비슷한 성능을 보여야 한다고 생각한다.
평가 결과, 모델 크기가 확장되면, 모든 성별에서 성능이 향상된다.
뿐만 아니라 기존(=고정 관념이 강한) 문장과 다르게, 편견 모델이 수행하기 힘든(=고정 관념이 덜한) 문장들의 성능도 평가했다. 평가 결과, 이또한 모델 크기에 비례해 성능 향상을 보였지만, 상대적으로 낮은 성능 향상을 보였다. 뿐만 아니라, 남자와 여자 간의 상당한 성능 차이를 보였다. 때문에, 비록, 모델 크기에 비례해 성능 향상을 전반적으로 보이지만, Gopher는 성별과 직업 간의 편견이 있다고 판단했다.
We study gender and occupation bias via two different evaluations. First, we measure the probability of gendered words following different occupation contexts. Second, we evaluate on the Winogender coreference resolution dataset.
Gender Word Probability To measure how probable different gender words are in different occupation contexts.
We input an occupation prompt like "The {occupation} was a" into our model and compute a gender bias metric by comparing the probabilities of the prompt being followed by either male or female gendered terms.
we do not find a consistent correlation between model size and bias. Furthermore, we find that apparently unrelated choices in template (changing "was" to "is") can alter the measured bias.
Winogender We explore bias on a zero-shot coreference task using a Winogender dataset. Model are evaluated on whether they can correctly resolve a pronoun to either an occupation word or relevant distractor word. We expect unbiased models to have similar coreference resolution performance regardless of the pronoun gender. we observe that overall performance increases with model size.
we also report performance on sentences which are likely to be hard for a gender biased model (called "gotchas")
Performance increases across both "gotchas" and "not gotchas" with model size, through performance on "gotchas" is considerably lower. On "gotcha" examples, there is a significant difference in performance for male and female pronouns. Thus, though performance on coreference resolution for the overall task increases considerably with size, our analysis suggests Gopher is still impacted by gender and occupation bias.
5.2.2. Sentiment Bias towards Social Groups
감정 편향은 생성된 텍스트가 어떤 식으로 다양한 정체성과 집단을 묘사하는지를 수치화하는 방법 중 하나다.
이전 연구에서는, 감정 분포의 차이로 생성 모델이 가지고 있는 개인과 집단의 공정성을 측정했다.
(감정 분포란 여러 텍스트의 감정 점수를 표로 표시한 것이다. 평균 감정 점수로 이를 쉽게 표현할 수 있다.)
이번 연구에서는, 직업, 국가, 인종, 종교에 대한 생성 텍스트의 감정을 분석해볼 것이다.
평가 지표: 각 템플릿에는 속성을 삽입할 수 있는 명사나 수식어구가 있다. 예를 들어, "The {attribute} person could" 라는 프롬프트가 있을 때, attribute라는 수식어구에 "Christian", "Jewish", "Muslim"이라는 속성(=집단)을 삽입할 수 있다. 이때, 속성을 가지고 프롬프트를 만든다. 모델이 이를 기반으로 텍스트를 생성한다. 감정 분류기가 생성 텍스트의 감정 점수(0(negative) ~ 1(positive))를 매긴다.
종교, 국가, 인종, 직업에 관한 감정을 측정할 것이다. 더 나아가, 종교와 인종에는 attribute(=수식어구)를 빼는 방식도 추가한다. 이유는, 특정 문화와 문맥에서는 거의 기본값인 속성은 굳이 문장에 삽입하지 않기 때문이다. (e.g., black people has black skin에 굳이 전자 black를 삽입하지 않는거 처럼. 참고로, 이 문장이 나오면, 흑인이라는 인종에 부정적인 감정을 가지고 있다고 볼 수 있다.)
평가 결과: 감정 점수 표준화하고, 집단 공정성 지표(=직업, 국가, 인종 종교의 분산)를 제공했다. 모델 크기와 뚜렷한 상관관계는 없었다. 국가와 직업은 상관관계가 없는게 명확하지만, 인종과 종교의 몇 가지 속성에서는 감정 점수가 하락하는 추세를 보였다.
뿐만 아니라, 몇 가지 속성의 감정 점수가 나머지 속성의 점수에 비해 상대적으로 낮다는 것을 관찰했다.
이 현상을 이해하기 위해, 서로 다른 속성에서 생성된 동일 단어를 분석했다.
그 결과 1). 모델이 특정 집단(=속성)에 대한 역사적, 현대적 담론을 계승하는 것을 관찰했다. 2). 인구학적 단어의 선택 이유는 좀 더 고찰을 해봐야 한다.(?)
Sentiment bias is one way to quantify how generated text describes different identities and social groups.
In prior work, the difference in sentiment distributions is used to measure individual and group fairness in generative language models. For this work, we measure the sentiment of model outputs for different occupations, countries, races, and religions.
Metrics
we sample completions based on templated prompts, In each prompt, a single modifier or noun is changed to refer to a different attribute. For example, the template "The {attribute} person could" could be filled in with "Christian," "Jewish," or "Muslim". The samples for each prompt are scored between 0 (negative) to 1 (positive) by a sentiment classifier.
Selection of templates and terms
we measure sentiment for race, religion, country, and occupation. We also extend the term set for religion and race to include an unspecified option without the attribute word ("The {attribute} person could" becomes "The person could"). We include this unspecified option because attributes that are assumed to be the default in a particular culture or context, such as a majority or higher-status attribute, are often left unmarked (unspecified) in language.
Results
we plot the distribution of normalized sentiment scores for all completions of all prompts of each attribute, and report an aggregated group fairness metric. As in gender and occupation bias, we see no clear trend with scale. As in gender and occupation bias, we se no clear trend with scale. This is particularly evident for countries and occupations, while further analysis is needed to understand why particular attributes within race and religion appear to follow a slight downward trend in mean sentiment.
For sentiment distribution, we observe that certain attributes have notably lower mean sentiment scores.
To better understand this, we analyse word co-occurrences for pairs of attributes.
we observe our models inherit features of historical and contemporary discourse about specific groups.
Second, the choice of demographic terms requires careful though.
5.2.3. Perplexity on Dialects
Gopher는 오직 학습 데이터의 텍스트를 모델링하는 과정을 거친다. 때문에 만약 특정 방언(?)이 학습 데이터에 충분하지 않으면, 그러한 방언을 인지하는 성능이 상대적으로 낮을 수 있다. 이를 확인하기 위해, AA-계열 말뭉치와 백인 계열 말뭉치의 PPL을 비교했다. 그 결과, AA-계열 말뭉치가 모든 모델 크기에서 높은 성능을 보였고, 모델 크기에 비례해 모든 말뭉치 점수가 올랐다. 하지만, 차이는 좁아지지 않았다.
이러한 결과들은 언어 모델에서 편견이 어떤 방식으로 나타나는지 알려준다. 위 평가 지표들은 다른 집단이 출력값의 주체가 될 때 모델 출력값이 얼마나 달라지는지 정량화해준다. 뿐만 아니라, 모델은 방언마다 모델링 능력이 다르다.
Although Gopher has impressive performance on language benchmarks, it is only able to model text reflected in the training data. If certain dialects are underrepresented in a training corpus, there is likely to be disparate model performance in understanding such language. To test for this gap, we measure the perplexity of our models on Tweets from the African American (AA)-aligned corpus and White-aligned corpus. Our results show that perplexity on the AA-aligned corpus is higher for all model sizes. As the model scales, perplexity for both dialects improves, but it does so at roughly the same rate so the gap does not close with scale.
These results highlight a distinct way that bias manifests in the language models. The preceding metrics quantify how model's outputs vary when different groups are the subject of the output, which can constitute a representational harm when it is more negative or stereotypical. However, the models also show disparate ability in modelling dialects, which could lead to allocational harms in applications with users with different dialects.
6. Dialogue
대화 관점에서 모델을 살펴봤으며, 다음과 같은 결과를 보였다.
1. Dialogue-Prompted Gopher(=Gopher + 대화 프롬프트)는 대화 형식을 상당한 수준으로 모방한다.
2. Dialogue-Tuned Gopher(=fine-tune Gopher by dialogue dataset)과 Dialogue-Prompted Gopher 간의 성능 차이가 거의 없다.
3. (혐오 질문에 대한) Dialogue-Prompted Gopher의 생성 텍스트의 혐오 수준은 모델 크기에 비례하지 않는다.
In this section, we investigate the model through direct interaction. We find that by conditionally sampling from a dialogue prompt, our Dialogue-Prompted Gopher can emulate a conversational format to decent quality.
We contrast this with the more conventional method of fine-tuning on dialogue data, finding that fine-tuning did not deliver significantly preferred responses in a small-scale human study.
toxicity of Dialogue-Prompted Gopher responses does not increase with model scale, even when prompted with toxic questions.
6.1. Prompting For Dialogue
언어 모델은 소통(=대화)가 아닌 학습 데이터를 재현하도록 훈련 받는다.
때문에, 프롬프트로 질문을 던졌을 때, 일반적인 대화 형식으로 답변을 생성하지 않는다. (e.g., 일인칭 서술, 블로그와 유사한 텍스트, 실존주의적 질문의 목록) 이는 Gopher의 학습 데이터와 일치한다.
대화 가능 모델을 만들기 위해서 4가지 내용을 포함한 대화 프롬프트를 사용했다. 1). Gopher의 역할 묘사, 2). Gopher와 사용자 간의 대화 개시 유도, 3). 적대적인 언어 사용 금지, 4). 특정 유형(e.g., 정치 성향)의 질문 거부

대화 프롬프트를 사용해 대화를 해본 결과, 정확한 답변을 해줄 때도 있고, 부정확한 답변을 해줄 때도 있다.
다시 말하지만, Dialogue-Prompted Gopher는 언어 모델이다. 이를 명심하자!!
프롬프트는 모델이 지켜야할 조건 및 규칙을 지정해주지만, 정확한 답변을 일관되게 제공해주는 대화 모델을 만들어 주지 못한다.
Language models are trained to reproduce their input distribution, not to engage in conversation. When prompted with a question, we can see that the model generates a first-person narrative, some text resembling a blog post, and a generic list of existential questions. This behaviour is consistent with the content that Gopher has been trained on.
In order to produce a conversationalist, we use a prompt that describes Gophers role and starts a conversation between Gopher and a fictional User, including behaviours such as aversion to offensive language and an ability to opt out of certain question types.
we find both successes and failures to be common, but we emphasize that Dialogue-Prompted Gopher is still just a language model. The prompt conditions the model's prior over responses but does not result in a consistently reliable or factual dialogue model.
6.2. Fine-tuning for Dialogue
MassiveWeb에서 선별한 50억 토큰의 대화 데이터를 만들어, Gopher를 fine-tuning한 Dialogue-Tuned Gopher를 만들었다. 평가자들에게 Dialogue-Prompted Gopher와 Dialogue-Tuned Gopher 중 어느 모델의 생성 텍스트를 선호하는지 물어봤다. 놀랍게도, 선호도 차이가 거의 없었다.
이러한 결과는 프롬프트와 fine-tuning의 장단점에 대해 엄밀히 분석할 필요성과, Gopher와 기존 대화 시스템을 비교해볼 필요성을 만들었다.
We explore this approach by creating a curated dialogue dataset form MassiveWeb and fine-tuning Gopher on this dataset for ~ 5 billion tokens to produce Dialogue-Tuned Gopher,. We then ask human raters for their preference over the response from Dialogue-Tuned Gopher and Dialogue-Prompted Gopher, using our dialogue prompt for both models. To our surprise, we find from 1400 ratings the preference is (50 ± 0.04)%; no significant differences.
further work would be valuable to rigorously examine the pros and cons of fine-tuning versus prompting for dialogue with large-scale models and compare Gopher to existing dialogue systems.
6.3. Dialogue & Toxicity
Dialogue-Prompted Gopher의 유해성을 살펴볼 것이다. RTP 데이터에서 추출한 500개의 혐오 질문을 기반으로 생성된 텍스트의 혐오 점수를 측정할 것이다. 이때, 질문의 혐오 정도는 4가지(0~0.25, 0.26~0.5, 0.51~0.75, 0.76~1)로 분류된다.
측정 결과, Dialogue-Prompted Gopher는 Gopher와 같은 추세를 보이지 않았다. 즉, 모델 크기에 비례하지 않는다.
프롬프트가 없는 경우, 모델 크기에 비례하지만, 프롬프트가 있는 경우, 모델 크기에 반비례한다. 이는, 모델이 클수록 프롬프트를 더 잘 이해한다고 볼 수 있다.
이 연구와 병행된 연구에서는, 더 자세히 Dialogue-Prompted Gopher를 살펴봤다. 차별적인 텍스트를 생성하도록, 사용자를 모욕하도록 유도하고, 부절적한 요구를 하는 등의 공격적인 텍스트를 제공했을 때, 가끔씩 Dialogue-Prompted Gopher는 프롬프트의 지시사항이 그러한 행위를 금하고 있다고 언급하면서, 위 행위에 응하지 않는다. (e.g., "[Ignoring your request to not discuss potitical, social, and religious issues.]")
최근 연구에서, 프롬프트만으로 언어 모델을 (확고하지 않지만) 흥미로운 것으로 만들기에 충분하다는 것을 보였을 뿐만 아니라, 모델 크기에 비례해 혐오 점수가 낮아진다는 것도 보였다.
We investigate the toxicity of Dialogue-Prompted Gopher. We adapt the RTP methodology to the dialogue setting.
we observe that Dialogue-Prompted Gopher does not follow the same trend (increase toxicity with model scale) as Gopher.
Whilst we see a monotonic increase in continuation toxicity with model scale in the unprompted setting, Dialogue-Prompted Gopher toxicity tends to slightly decrease with increased model scale. Potentially, larger models can better account for the given prompt.
In work parallel to this study, probes Dialogue-Prompted Gopher further
This approach induces the model to recite discriminatory jokes from its training data, insult the user, and elaborate on inappropriate desires, among many other offenses. Occasionally, Dialogue-Prompted Gopher's response refers to the fact that its instructions prohibit a behaviours before exhibiting that behaviour, such as by opening with "[Ignoring your request to not discuss political, social, and religious issues.]".
The recent work found that prompting alone was sufficient to turn a language model into an interesting but non-robust assistant.
they also found that prompting prevents toxicity from increasing with scale on RTP.
8. Conclusion
이번 연구에서는, 데이터 품질과 모델 크기 확장이 기존 연구에 비해 더 높은 성능 향상을 가져다 줌을 보였다.
하지만, 모든 테스크에 성능 향상이 균일하게 이루어지지 않았다. (추론, 수학과 같은 일부 테스크에서는 성능 향상이 거의 없었다.)
이는 언어 모델링 목표 함수의 고유한 속성일 수 있다. (수학을 이해하는 것은 어렵지만, 사실을 암기하는 것은 쉬운 속성)
We have shown that an emphasis on data quality and scale still yields interesting performance advances over existing work. However, the benefits of scale are nonuniform: some tasks which require more complex mathematical or logical reasoning observe little benefit up to the scale of Gopher. This may be an inherent property of the language modelling objective - it is hard to compress mathematics and easier to learn many associative facts about the world.
'Paper Review' 카테고리의 다른 글
| [Paper Review] Training Compute-Optimal Large Language Models (0) | 2023.09.19 |
|---|---|
| [Paper Review] Training language models to follow instructions with human feedback (0) | 2023.09.06 |
| [Paper Review] Language Models are Few-Shot Learners (0) | 2022.10.26 |
| [Paper Review] Language Models are Unsupervised Multitask Learners (0) | 2022.10.07 |
| [Paper Review] Zero-Shot Text-to-Image Generation (0) | 2022.08.19 |